

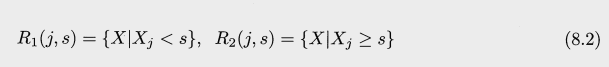
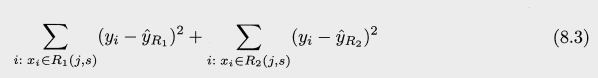
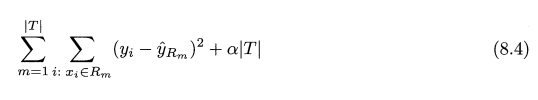
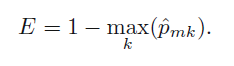


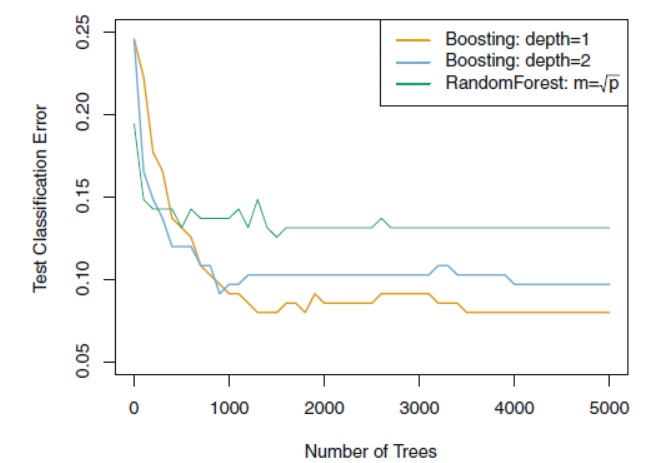

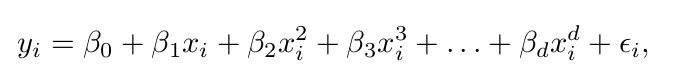

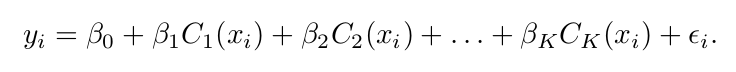



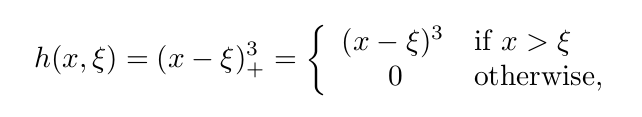


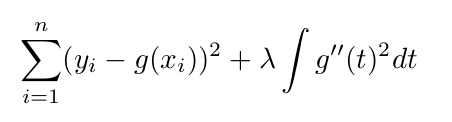







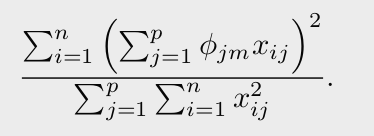



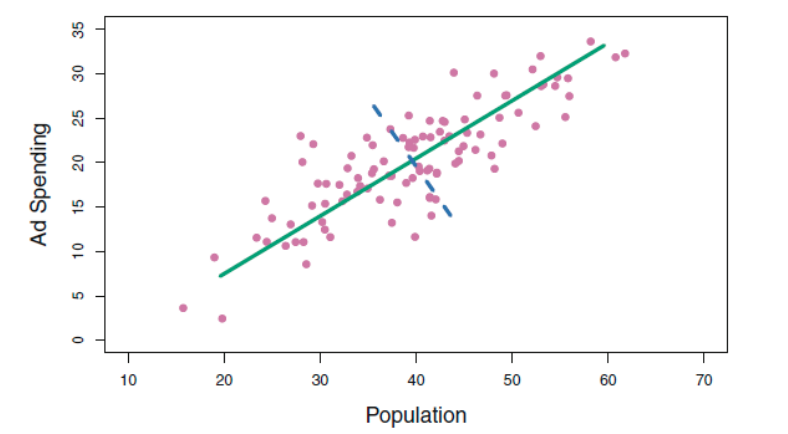
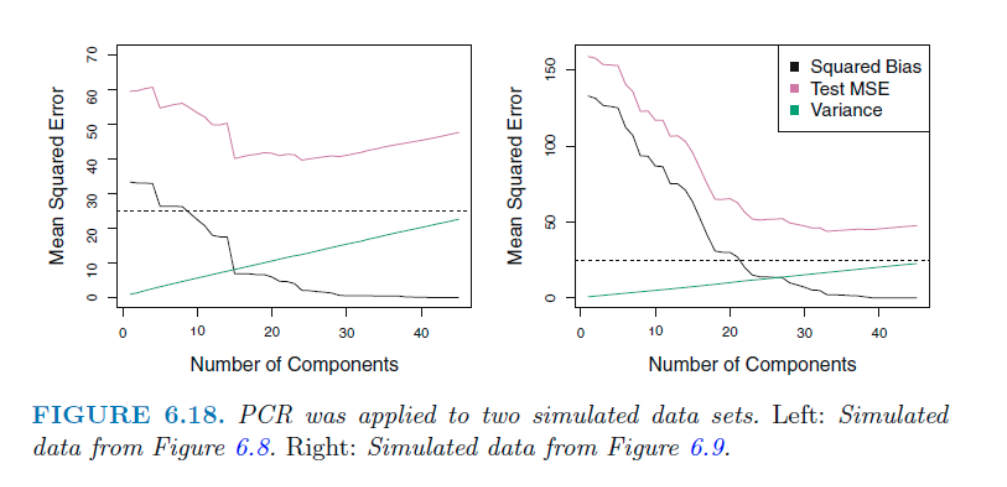



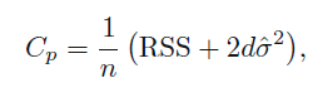
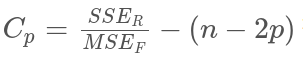




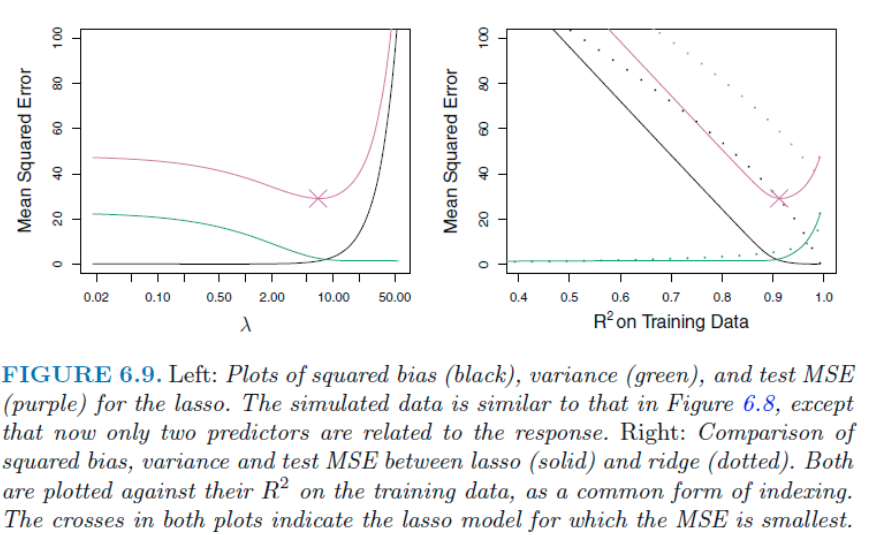

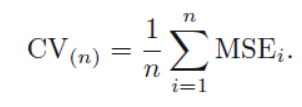








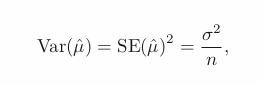
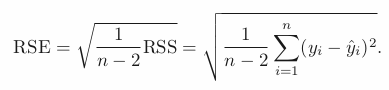




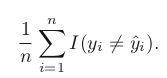
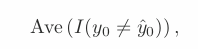


Reference:
- An Introduction To Statistical Learning with Applications in R (ISLR Sixth Printing)
- https://godongyoung.github.io/category/ML.html
Clustering
관측치들을 각 그룹별로 나누는데. 해당 그룹내의 관측치들은 유사하게, 다른 그룹의 관측치와는 상이하게 나누는것. 이 유사/상이 하다를 정의를 domain-specific (도메인 특정) 을 기반으로 한다
클러스터링이 비지도 (unsupervised) 방식인 이유는, 자료를 기반으로한 구조 (structure)를 발견, 그룹을 나누는것인데 비해, 지도 방식의 경우 어떠한 결과를 유추/예측 하고자 하는것.
Clustering AND PCA 모두 summary를 통해 데이터를 간단하게 하려 하지만
- PCA: 분산의 많은 비율을 설명하는 관측치들을 저차원 표현으로 찾으려 함
- Clustering: 관측치들중 같은 서브그룹을 찾으려 함.
즉 클러스터링은 사람들 (관측치)들중 이 제품을 잘 살것같은 그룹을 찾아내는 형식 - market segmentation 이라고도 한다.
K - mean clustering
미리 지정한 수의 클러스터로 나누는것.
이 k 개의 클러스터간 서로 절대 겹치지 않으며 모든 관측치들은 어느 한 클러스터에 속해있다.
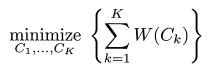
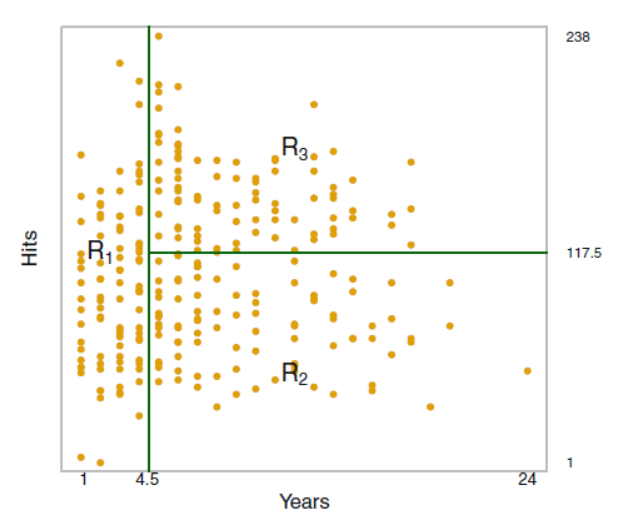
위의 식에서 유추할수 있듯, 한 클러스터 내에서의 변동이 가장 적은 클러스터링을 목표로 하고 있다.
이 변동 W(Ck) 를 정의 하는 방법은 여러가지 이지만 가장 일반적으로 유클리드 거리 제곱 (squared Euclidean distance)를 사용한다. 이를 적용하면 위의 식이 다음과 같이 변한다.
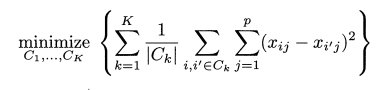
Ck = 클러스터내 관측치들의 수. 관측치들 사이의 pairwise한 거리의 제곱의 합을 관측수로 나눈것.
물론 위의 모든 방식을 사용하려면 K ** n 개의 분할 방법이 존재하기에 다음과 같은 알고리즘을 사용한다.

즉 랜덤하게 클러스터를 분배하고, 각 클러스터의 관측치들의 centeroid 를 벡터 중간값으로 정한후, 가까운 클러스터로 다시 재분배, 반복하는것. 해당 재분배가 (클러스터의 변화가) 없을때가지 반복하는것.
물론 이러한 방식은 초기 클러스터가 어떻게 분배 되느냐에 따라 달라지는 국소 최적 (local optimum) 이다 따라서 이를 피하기 위해 랜덤 할당을 다르게 해서 여러번 실행해보고, 위의 식의 값이 가장 작은것을 선택한다 ( = gloabl optimum) K 숫자 선택은 이후에 다뤄진다.
Hierarchical clustering
K-mean clustering 이 가지고 있는 단점: K 를 미리 지정해야 한다 이 없는 방식이며, dendrogram 이라고 하는 tree-based 로 표현한다
bottom-up (위로) and agglomerative (융합) 클러스터링을 설명하는데 이들은 가장 보편적인 계층적 클러스터링 ‘방식이다.
해석
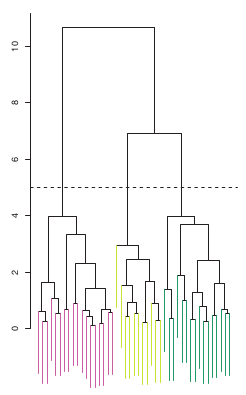
밑의 (잎) 이 위로 올라가며 가지로 융합되는 모습이다. 이 융합되는 트리의 높이가 낮을수록 관측치간의 유사성이 더 높음을 뜻한다. 또한 그림으로 한눈에 다른 색 (다른 그룹)이 서로 융합되는 높이를 알수도 있다. . 위의 그래프의 경우 초록 노랑의 융합이 빨강보다 더 빠르기에 초록 노랑이 더 유사함을 알 수 있다.
주의할 점은 이 관측치의 유사성은 수평 (즉 옆에 가까이 있냐) 수준이 아닌 수직 (융합이 언제 일어나느냐) 로 판단해야 한다. 덴드로그램을 절단하는 수평선이 곧 k의 수이다. 위의 그래프는 5에서 절단함으로써 3개의 클러스터링을 얻는다.
다만 덴드로그램은 TREE 이기때문에 2개씩으로 밖에 나눌수가 없음. 즉 프랑스미국영국을 나눌때 프랑스 | 미국영국 이후 프랑스 미국 영국 과 같이 두번에 걸쳐 3번에 나눈다. 결국 각각의 다른 그룹이 2번에 걸쳐 나눠지는 이러한 형태때문에 가끔 k-mean clustering 보다 정확도가 낮은 결과를 나타낼수 있다.
알고리즘
각 관측지의 페어마다 비유사성 (dissimilarity)를 정의한다 (유클리드 거리를 가장 많이 사용).
덴드로그램 바닥의 n 개의 관측치에 n 개의 클러스터를 주고, 가장 가까운것끼리 합쳐서 결국 1개의 클러스터가 될때까지 진행한다.

위의 알고리즘은 문제를 가지고 있는데, 여러 관측치를 가지고 있는 클러스터간에 비유사성은 어떻게 정의 하는가 이다. 이를 해결하기 위해 완전연결 평균연결 단일연결 무게중심연결을 사용하는데 보통 평균,완전. 단일을 많이 사용한다. 평균,완전 연결이 균형잡힌 덴드로그램을 제공하는 경향이 있어 더 선호된다.
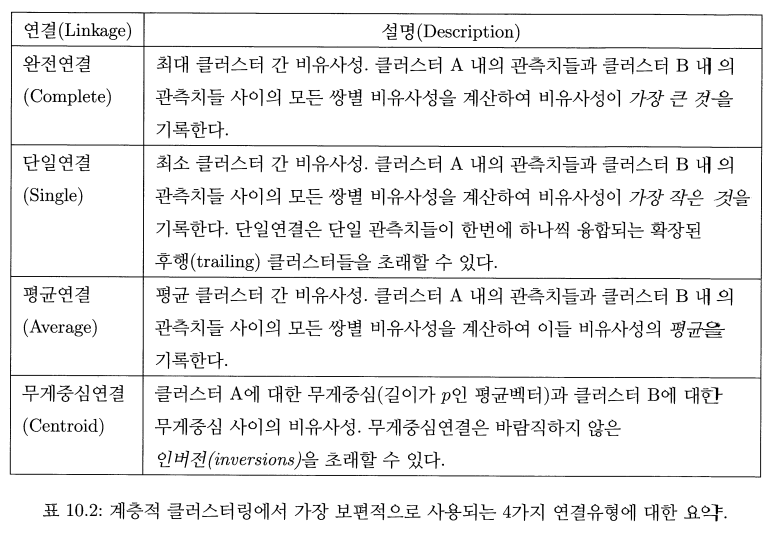
비유사성 측도
현재까지 유클리드 거리를 사용했으나, correlation-based distance 같은 방법은 상관성만 높다면 거리가 떨어져있어도 유사하다고 간주하는 방법이다. 즉 유클리드는 소비자가 구매한 양끼리 묶어서 클러스터링을, 상관 기반 거리는 비슷한 물품을 구매한 소매자끼리 묶는 방식이다.
또한 비유사성의 경우 표준편차가 1이 되도록 스케일링을 고려해야 할 수 있다 (단위차이를 없애기 위해)
이슈
클러스터링은 매우 유용하지만 여러 이슈도 존재한다.
큰 결과 작은 결정 (small decision with big consequences)
- 표준화과 진행되어야 하는가? 평균 = 0, 표준편차 = 1 이 되도록 스케일링 되어야 한다등등
- 계층적 클러스터링의 경우
- 어떤 비유사성 측도를 사용할것인가
- 어떤 연결을 사용해야 하는가
- 어디서 덴드로그램을 절단해야 하는가
- K-평균 클러스터링의 경우 몇개의 클러스터를 사용해야 하는가
이러한 작은 결정들은 결과에 큰 영향을 미친다.
검증
찾은 클러스터들이 단지 아웃라이어 (노이즈)의 결과인지 아니면 진정 어느 한 부분그룹을 대표하는 (나타내는) 클러스터인지 검증해야 한다. 이를 위해 p값을 할당하는 기법들이 존재하지만 무엇이 딱 좋다 말할수는 없다
다른 고려사항
k-mean clustering and 계층적 클러스터링 모두 각 관측치에 하나의 클러스터를 할당한다. 이러한 행동은 outlier 들의 존재로 클러스터가 심하게 왜곡될수 있다. mixture model 은 이러한 특이점을 수용하는 방법인데 k-mean clustering 의 soft 버전이라고 할 수 있다.
또한 클러스터링 방법은 작은 변동 (perturbations)에 robust 하지 않다. 이는 n개의 관측치에서 몇개를 제외하고 클러스터링을 다시 진행하면 보통 그 전의 클러스터링과 유사하지 않다.
결과 해석및 접근 방법
위의 이유들로 인해 여러번 클러스터링을 하고, 지속되는 패턴을 찾는것이 좋다. 클러스터링이 얼마나 robust 한지 감을 잡기 위해 부분관측치에 대해 클러스터링을 수행하는것도 좋다.
중요한점은 분석결과인데, 이러한 결과로 인한 결과는 절대적으로 신뢰해서는 안되며, 단지 가설 개발에 이용되어야 한다.

