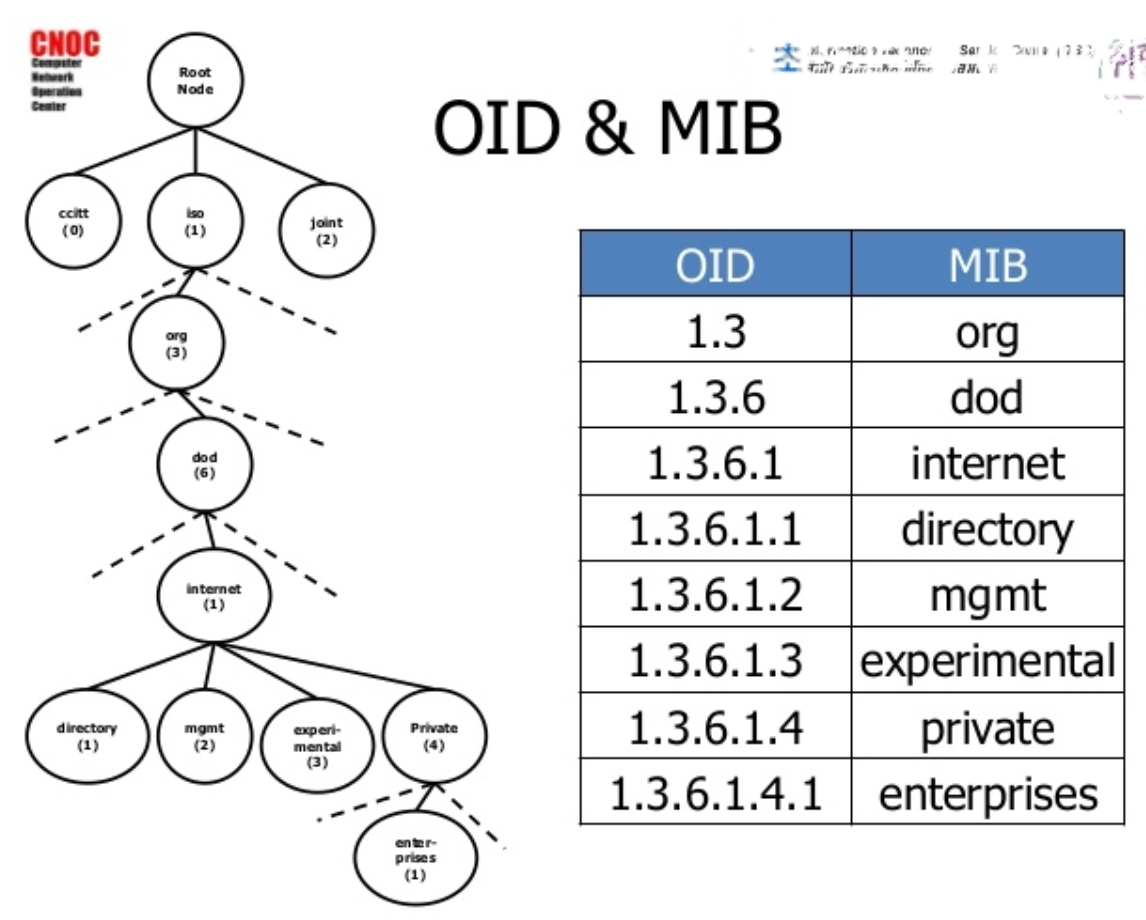
Reference:
Q: Why is the layer model for networking good idea?
A: 레이어들은 어느 기능등이 제공및 미제공 되는지에 대해 명확하게 해준다 (각각의 레이어의 서비스들의 명확성). 필요한 기능들이 무엇인지, 그리고 상/하 레이어와의 관계, 그리고 존재하는 기준들의 사용등.
Q: What’s a Protocol Data Unit, and what is a Service Data Unit?
A: PDU는 말 그대로 네트워크 프로토콜을 통한 두 종단간의 정보교환 패키지를 말한다 (전송은 세그먼트, 네트워크는 패킷 응용계층은 데이터/메세지). SDU는 보통 API 를 통한 두 레이어간의 한 종단 지점에서 교환되는 정보 패키지를 말한다 (캡슐화 되서 넘어갈때). PDU는 같은 레이어의 교환이고 SDU는 한 모델안에서의 수직적 교환이다.
Q: What’s the difference between a Frame and a Packet?
A: 프레임은 랜 프로토콜에서 (데이터 링크) 전송되는 다양한(불분명한) 길이를 말한다. 패킷은 변수-길이 (정해진) 화물을 가지고 전역 네트워크로 전송되는 것을 지칭한다 (아이피 패킷같은). 데이터그램이나 세그먼트와 다르게 UDP or TCP와 같은 인터넷 프로토콜로 전송된다.
Q: Why do we think of IP as being ‘end-to-end’ between hosts, and TCP/UDP as being ‘end-to-end’ between applications
A: 즉 아이피는 각 호스트 (기계들) 의 연결을, TCP/UDP는 어플리케이션 연결이 주된 임무라서.
- 아이피는 다양한 종류의 랜 기술과 라우터등을 통한 광역-구간 (인터넷)에서 기계간의 연결을 제공한다. 랜과 라우터등은 필요한 정보만을 읽은뒤 이 패킷들을 올바른 지역으로 보내주는 역할 (물론 체크섬이나 홉, 그리고 NAT의 경우 아이피 주소와 포트등을 수정하기도 한다). 운영체제는 패킷을 받고 언팩한다 (포트가 운영체제에게 키를 전달해준다). 아이피는 종단에서 다른 종단을 찾아 내는데 필요하다.
- 어플리케이션은 TCP/UDP (외 다른 프로토콜) 를 서로간 대화하는데 필요로 하는데, 포트는 운영체제에게 키를 제공함으로써 패킷 수하물 (페이로드)가 올바른 어플리케이션으로 전송되게 한다. 라우터와 다른 기기들은 (NAT와 깐깐한 네트워크 보안을 제외하고) 패킷안의 내용을 확인하지 않는다. TCP/UDP 는 어플리케이션끼리 이야기 하는데 필요한 프로토콜, 종단간의 위치를 찾는데는 사용되지 않는다.
Q: Why does the IETF standards process look for ‘rough consensus and running code’?
A: IETF (프로토콜 표준화 기구). The phrase is often extended into the saying “rough consensus and running code”, to make it clear that the IETF is interested in practical, working systems that can be quickly implemented. (거친 합의란, 모든 사람이 동의할 필요는 없지만, 관련자들간에 사용 될 수 있도록 합의된 상황이다. - 정치권에서 정당내에서 의견이 다르지만, 정당의 의견을 거친합의로 모은후 대중에게 알리는것과 같은것). 표준화를 만든다는것은 매우 복잡하고 끝이 보이질 않는 작업이다 (RFC 는 표준화 프로토콜의 공식 문서다). 프로토콜은 RFC문서에 명확한 기준을 가지고 명시되는데 이는, 다른 사람과 당신이 서버/클라이언트에서 통신할 수 있도록 가능케 해준다. 즉 이 거친 합의는, 모두가 이 프로토콜을 따르지는 않지만, 이 프로토콜을 따르는 사람들 끼리의 통신을 가능하게 한다.
Q: Which IP header and which ICMP packets are important for traceroute to find the path of packets? Why? (how does it use them?)
A: ICMP (Internet control message protocol). TTL값은 IP 데이터그램이 인터넷 시스템 내에서 존재할 수 있는 시간의 상한선으로 볼 수 있다. TTL 필드는 데이터그램의 송신자에 의해 설정되며, 목적지까지의 전송 경로에 있는 모든 라우터들에 의해 그 값이 감소된다. 목적지에 다다르기 전에 TTL 필드의 값이 0이 되면 해당 데이터그램은 폐기되고 ICMP 에러 데이터그램 11 - Time Exceeded가 송신자에게 보내진다. TTL 필드의 목적은 전달되지 못한 데이터그램이 인터넷 시스템 내에서 지속적으로 순환하여 넘쳐나게 되는 상황을 방지하는 데에 있다. Traceroute는 1부터 선형적으로 늘어나는 TTL을 포함시켜 목적지로 보낸다 (죽으면 하나 늘려서 다시 보내고 등등). Each router will decrease the TTL by one, our server on the other end will receive an IP packet with a TTL of one and replies with an ICMP reply to H1. We now know that the destination is reachable and we have learned all routers in our path. Each IP packet that we send is called a probe. Traceroute can be used with ICMP, UDP and TCP, depending on your operating system.
정리: TTL이 0이 될때마다 라우터는 자신의 아이피 주소와 시간초과 패킷을 보내고, 서버또한 수신 응답 메세지를 보내므로, 서버까지 도달하는 라우터들의 주소 즉 경로들을 알 수 있게 된다. 이 방법은 최단 경로를 항상 의미 하지 않으며, 최단 경로를 제공 받는 경우는 라우팅 테이블이 최적으로 관리되고 있을때만이다.
Q: Given some /25 address range, how many hosts could we potentially have on our network? What does the /25 netmask look like in dotted-quad notation?
A: 네트워크 주소는 총 4바이트로 32비트이다. /25는 첫 25비트가 호스트 주소이고 나머지 7비트가 내 개인 주소가 된다. 2의 7승은 128인데 1개는 유선, 1개는 브로드캐스트 주소를 빼면 128-2 = 126개가 된다.
/25 넷마스크는 첫 25 자리가 모두 1이라는 뜻이므로 255.255.255.128 이 된다. 즉 128~255 사이의 128개 중 126 개가 가능한것.
Q; What’s the benefit of using the longest-prefix rule in forwarding table?
A: 수많은 주소들은 한 곳에 축약할 수 있음 (이 프리픽스에 해당하는 주소들을 프리픽스로 통합이니까). 이로 인해 예외적인 주소들을 추가 하고 싶으면, 해당하는 주소 한개만 더 추가하면 됨 (프리픽스 안에 주소 중 하나여도). aggregate an entire network’s worth of host addresses into a single entry. 장점은: 경로 찾기의 성능향상, 비용 감소, 안전성 증가.
IPv4 주소
Q: Why would a host send a Gratuitous ARP frame?
A: 쓸데 없는 ARP란 답변을 바라지 않는 브로드 캐스팅 패킷이다. 패킷안에는 송신자와 수신자 모두 같은 아이피를 가지고 있으며, 맥주소는 브로드캐스트 주소이다. 유용한 이유로는 다음이 있다.
- 아이피 충돌 감지. 해당 패킷을 받은 머신은 자신의 아이피와 비교후 충돌하는지 알 수 있다.
- 먼 DHCP에게 아이피를 받는 경우도 있어서 중복될 경우 충돌 확인이 가능하다.
- 혹은 자신이 아이피를 바꿀 경우에도 1,2번 모두 도움 가능.
- 다른 머신들의 ARP 테이블 업데이트를 도운다 (라우팅 테이블 같은거)
- 각 머신의 맥 주소 스위치에게 어는 포트로 연락을 취해야 하는지 알릴수 있음. (스위치는 해당 네트워크 세그먼트를 향한다고 생각하면 된다.)
Gratuitous_ARP