
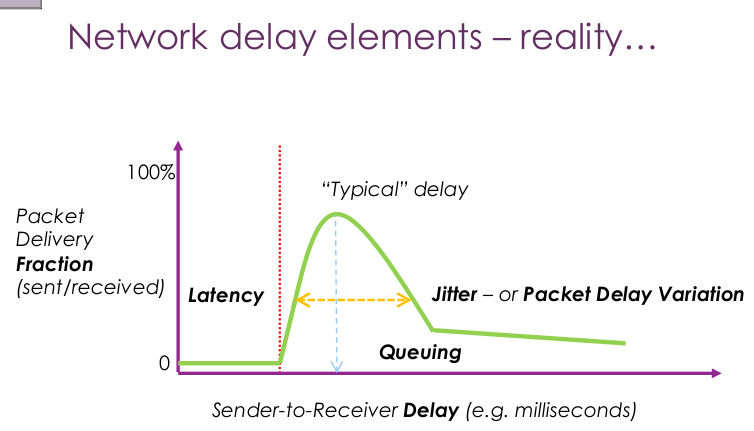

Q_1: What causes the ‘latency’ on the left?
A_1: sender/receiver transmission 딜레이로 피할수 없는 딜레이 이다.
Q_2: What causes the long tail at the far right?
A_2: 도착하기 까지 여러 구간에서 다양한 이유로 멈춰진 패킷들의 도착
Q_3: What would cause jitter to become very large?
A_3: 지터는 다양한 넓이의/종류의 딜레이를 나타낸다. 아마도 이와 같은 경우는 중간에 경로가 다양하게 바뀌었거나, 해당 경로의 라우터들의 load가 갑자기 바빠지거나 한듯하다
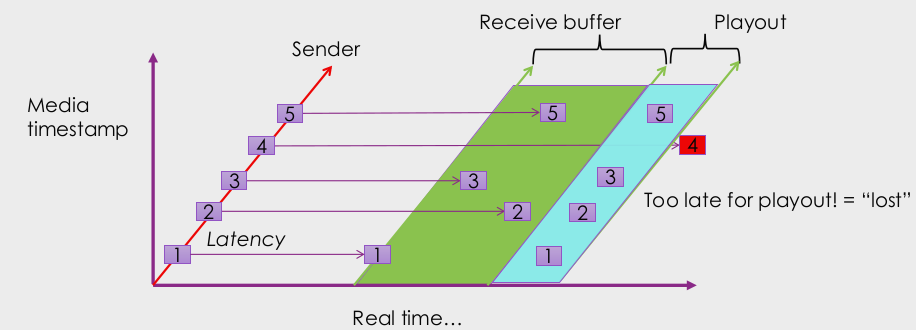
Q: Why is packet 4 not able to be played out, since it was received? How could we fix that? What problem does that cause?
A: 수신 버퍼의 길이가 패킷 4를 수신하기에 너무 짧았음. 이를 고치기 위해 버퍼의 길이를 더 늘릴수 있지만, 그렇게 하면 송신과 플레이 시간의 지연이 더 커질것임. 따라서 실시간이라 부르기 애매해진다 (내가 말하고 몇초뒤에 상대방이 답한다던가 하는것).
Q: Why is retransmission (except in multicast) generally a bad idea? Why is it ok in multicast?
A: 잃어버린 패킷을 감지하고, 재요청하고 (그 잃어버린 패킷을 아직 가지고 있길 희망하면서), 패킷을 받는과정이 너무 오래걸리기 때문. 물론 재요청해서 바로 받는다는 보장도 없다. 멀티캐스트에서는 retransmission 해주는 위치가 가까울수 있어서 지연이 줄어들기 떄문.
Q: Why are the performance problems reduced in streaming applications?
A: 문제는 여전히 존재하나, 이는 단방향 트래픽이기 때문에 딜레이를 알아차리지 못한다 (화상 통화가 아닌 트위치 같은거 말하는거). 이 뜻은 내가 받은 버퍼의 크기를 키워서 안정적인 (reliable) 프토토콜을 사용 가능하다는것. → 내가 트위치 볼때 안끊기기만 하면 되니까 이에 맞춰 버퍼만 키우면됨
Q: What are the main network and device issues for IoT? Why is it different to other devices connecting to the internet?
A: Scale, Power, Network, Timeliness, Reliability → 해당 자료 읽어볼것.
Q: As an application model, how is PubSub different to Client/Server? Why is it better suited to large-scale IoT applications?
A: 클라이언트와 서버는 1:1 관계를 가진다 반면에 PubSub은 데이터 진원지 (소스)와 publishing 하는것이 나뉘어져 있기 때문에 서버/브로커를 통해 구독자들이 정보를 얻을수 있다. 또한 확장성과 관련해서 n 개의 생산자와 m의 소비자들이 있다면, n*m 대신 n+m의 직접적인 관계를 유지 할 수 있다 (중간에 브로커 하나). 또한 이러한 관계는 오직 해당 토픽에 관심있는 구독자들에게만 정보를 push 하기 때문에 reducing load for producers and brokers.
Q: Why are MQTT packets so compact and simple? (compared to HTTP say)
A: 성능과 부하를 위해서 이다. 짧은 메세지는 대역폭을 거의 소모하지 않고 간단함은 패킷 구성에 관한 CPU 소모량을 줄일수 있다.
Q: Why does MQTT offer multiple levels of QoS (quality of service)? Why is there separate, potentially different, QoS on both sides of the broker (producer->broker, broker->consumer)?
A: 상황에 따라 해당 메세지가 반드시 ensure 해야 할지, 혹은 가끔 업데이트로 충분한지, 혹은 메세지를 놓치더라도 다음까지 기다릴수 있는지 등 요구조건이 다르기 때문이다. 해당 소비자가 그 정보에 대한 중요도가 다르기 때문에, 중요하게 여기는 소비자는 높은 QoS를 이용할것이고 아니면 낮은 레벨을 사용할 것이다. 이로 인하여 데이터 소모량에 대한 유연성을 가질수 있다 (QoS 레벨에 따라 데이터 필요량이 다르니까 - 커뮤니케이션 횟수가 다름)
- QoS 0 을 선호하는 사람들은 굳이 복잡한 QoS 2 안 써도 되니까.
Q: In what circumstances is it useful for a server to ‘retain’ an MQTT-published message?
A: 소스가 가끔 메세지를 주던지, 소비자가 언제던지 들어올수 있던지, 혹은 비안정적으로 연결되어 있던지 할때 좋음. 서버에 리테인 함으로써 위와 같은 상황에 현재 which state (메세지) 가 있는지 빠르게 배울수 있음. 즉 서버가 정보를 가지고 있으면 소비자가 재부팅하고 (그 사이에 정보를 못받았던, 정보가 초기화 되서 아무것도 모른다던지) 다시 들어와도 빠르게 “응 지금 메세지 이 상태임” 하고 알려줄수 있는거.

