Q: In the 7 layer model, what are some security ‘opportunities’ at each layer?
A:
Physical: Tapping (도청)
Link: break in and listen/interfere 와이파이, 이더넷
Network: break in and listen/interfere 라우터, 게이트웨이, 모뎀, 방화벽
Transport: see/modify 어플리케이션 대화
Applications: for access to content or to interfere
Q: The idea behind encryption is mainly seen as providing confidentiality. Why do we have both SSL/TLS and IPSec, if they do pretty much the same thing?
A:
SSL/TLS 와 IPSec 은 서로 다른 계층에서 실행된다 (트랜스포트, 네트워크) 따라서 다른 특징을 지님
TLS는 어플리케이션의 기밀성을 책임지지만, 여전히 출발지, 목적지, 포트 등의 정보를 드러낸다
IPSec 의 경우 본래 패킷에 대한 모든것을 숨기며, 터널을 제공함으로써 src / dest 에 대한 정보를 숨김
또한 IPSec의 경우 어플리케이션 계층을 커버하는 반면, TLS는 오직 어플리케이션만을 책임짐
Q: What does it mean to have ‘confidentiality’, ‘authenticity’ and ‘integrity’ of packets traversing the network? What about ‘freshness’?
A:
Confidentiality: 아무도 듣지 못함
Authentication: 상대방이 주장하는 신원이 확실하다고 믿음 (즉 본인확인)
Integrity: 패킷이 중간에 변질되지 않았음
Freshness: 패킷이 새로운것이며, 재사용되지 않음
Q: Why does TOR (onion routing) use 3 routers for passing traffic through?
A: 아무도 한번에 어디서 어디로 향하는지 알게 하지 못하게 src & dest. 이로 인해 그 누구도 양 종단에 대한 정보를 알지 못함.
Guard: Knows src
Middle: Knows nothing
Exit: Knows dest
Q: Why would a worker on the road use a ‘mixed-mode’ VPN connection to their office? What’s the benefit, compared to say a ‘transport-mode’ VPN?
A:
Mixed-mode 란 호스트와 라우터 같이 다른 기기가 연결된 모드를 말한다
이로 인해 이 호스트는 라우터에 속한 다른 기기들에게 마치 같은 LAN에 속한 기기처럼 보여질것
Transport Mode 는 호스트와 호스트를 직접적으로 바로 연결한다.
차이점은, 만약 해당 대화가 (communication) 이 point to point 형식이라면 Transport 모드를, 여러명과 대화해야 한다면 mixed-mode 가 더 적절하다.
Q: How does ingress filtering prevent (most) spoofing?
A:
라우터의 경우 해당 패킷이 어디서 온건지 알 수 있다.
예를 들어, 어느 패킷이 항상 어느 네트워크에서 오는지 알고 있다면, 다른 곳에서 오는 (특이하게도) 패킷의 경우 필터링이 가능한것.
이전과 다르게 다른 네트워크에서 온 패킷을 마치 spoofing 처럼 고려해서 그냥 드롭해버림.
Q: What are some the network feedback sources that help tell you when things are going badly somewhere on the network? 네트워크상에 안좋은 일이 일어나는지 어떻게 알 수 있나?
안 좋은일: 혼잡…?
A:
ICMP: 다양한 이유로 안 좋다는 사실만 알 수 있음; MTU가 너무 낮을수도, 높을수도 등등
IP 의 경우 신뢰성이 없으며 비연결 지향적이기에, 이를 보조하기 위해 ICMP 가 등장
ECN: 라우터가 혼잡이 생겼음을 알려줌, back off 해야 할지 알려주는 기준임
TCP Feedback (flow control) such as ACK Clock, SACK info, Jitter+latencry
ACK clock - ACK 가 오는 속도가 줄어드니까 알수 있음
SACK - 놓친 패킷에 대해 ACK 가 반복되니까 손실이 발생한지 알수 있음
Jitter + latency - 패킷 별로 도착하는 시간이 (variation) 다르니까 알 수 있음
Q: Why can’t we use all that feedback to measure what is going everywhere?
A:
왜냐하면 각각의 피드백은 그 path에 관한 내용인데, 이 경로가 고정된것도 아니고, 우리가 어떻게 조절할 수 있는것도 아님.
TCP feedback 들 또한 전체 경로중 혼잡이 발생한거지, 특정 경로, 위치에 대한 내용을 포함하고 있지 않음
결론: 정확한 위치에 대한 피드백을 받는것도 아니며, 그 위치를 알아도 고칠수 있는 방법이 없음
Q: What problems does SNMP solve?
A:
내 경로에 속하지 않은, 혹은 내 어플리케이션과 대화 하지 않는 네트워크 요소 (기기) 에 대한 상태를 확인 할 수 있게 해줌
Provides data that is standardised and that you can aggregate
이는 혼잡, 에러, 다른 문제들을 detect 할 수 있게 해준다. 특히 어느 기기가 문제를 일으키는지 모든 경로를 탐색하지 않아도 바로 알수 있음 (왜냐면 해당 기기의 상태를 확인만 하면 되니까)
IP 를 통해서는 알 수 없는 기기의 상태 (온 오프), 혹은 이벤트 발생등을 알 수 있다
물론 이를 가능케 하기 위해, 해당 네트워크 요소가 SNMP agent (or server) 기능을 가져야 한다
최근까지 보안도 안 좋았음.
Q: Why doesn’t it solve all those problems across the width of the Internet?
A: 내부 인터넷에 대한 정보를 알려주기 싫으니까. 덕분에 내가 권한이 있는 네트워크에 대해서만 사용 가능하다.
Q: Why do we want views over time and space?
A:
Views over Time (기간동안 살펴보는거) - 패턴
시간적으로 지켜봐야, 이 behaviour 가 정상인지 비정상인지, 혹은 우리가 보고 있지 않을때 일어났는지 알 수 있게 해줌.
혼잡이 짧은 시간동안 버스트 형태로 일어난건지, 아니면 해당 시간에 단순히 유저가 너무 많아서 expand 가 필요한건지 알려줌
즉 시간적으로 지켜봐야, 해당 행동의 정상 유무와 이를 해결하기 위한 방법을 알 수 있음
Views over Space (순간 순간 공간 (상황) 을 지켜보는거)
현 네트워크 상황의 스냅샷을 제공해주며, 이로 인해 우리가 지금 해결해야 하는 문제가 있는지 알려줌
예를 들어 어느 링크가 다운되었다 는 공간적 입장에서 현 상황이므로 해결되어야 함.
Q: Why does an SNMP trap get sent, and by whom?
A:
agent 가 manager 에게 보내는데, 이는 어떤 중요한 이벤트가 발생 했다는것을 알리는 알림이다
매니저로부터 요청받는 보통의 쿼리/응답 메세지가 아닌 6개 이벤트 (링크 다운업 등등) 이거나 제조사가 정의해 놓은 이벤트가 발생한것.
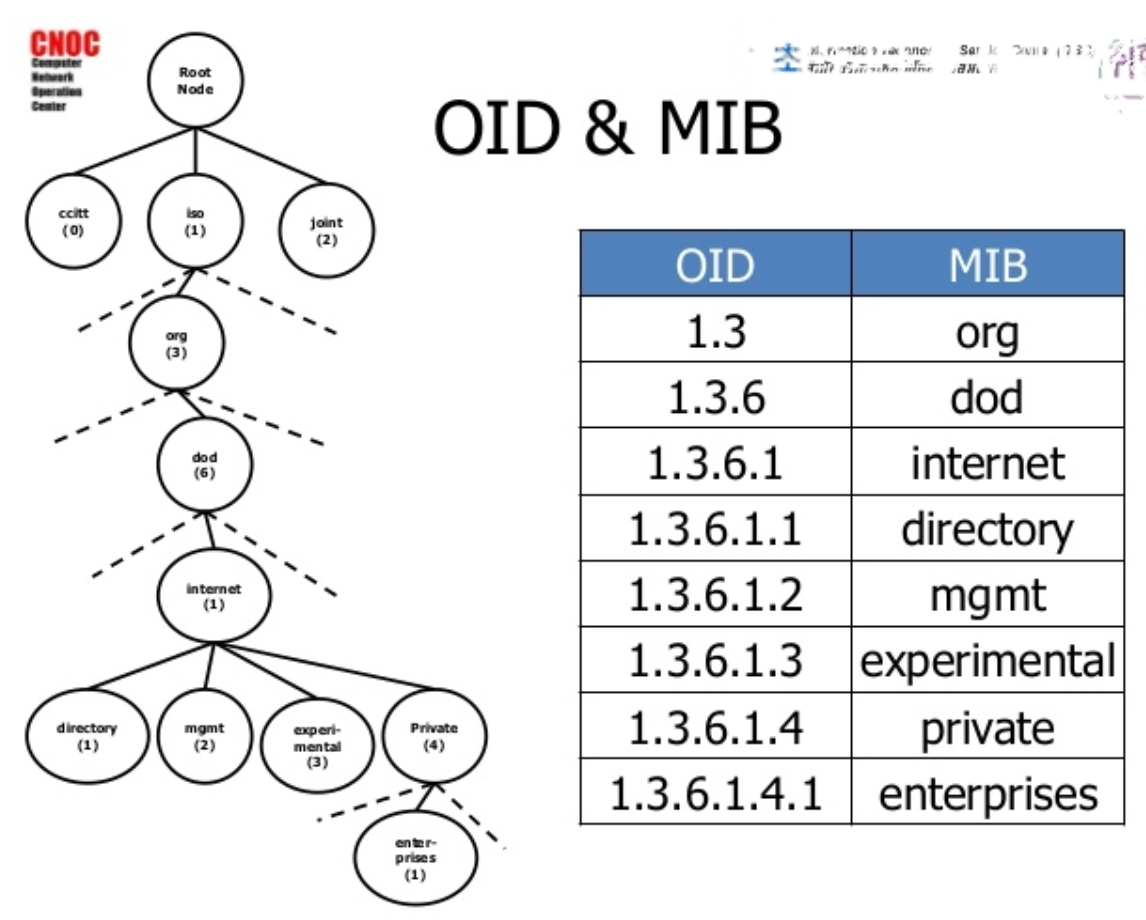
Q: What’s the point of a MIB?
A:
MIB 는 데이터베이스의 구조로, 다른 MIB 와 합쳐 질 수 있음 (나무 형식). 이로 SNMP agent 가 가지고 있는 데이터에 대해 모든 object는 unique 한 이름을 가질수 있다
MIB는 각각의 필드, 구조, 성격, 관계들을 정의 하며, 사람들이 읽을수 있는 설명도 포함하고 있음
Q: What is a ‘GetNext’ used for?
A:
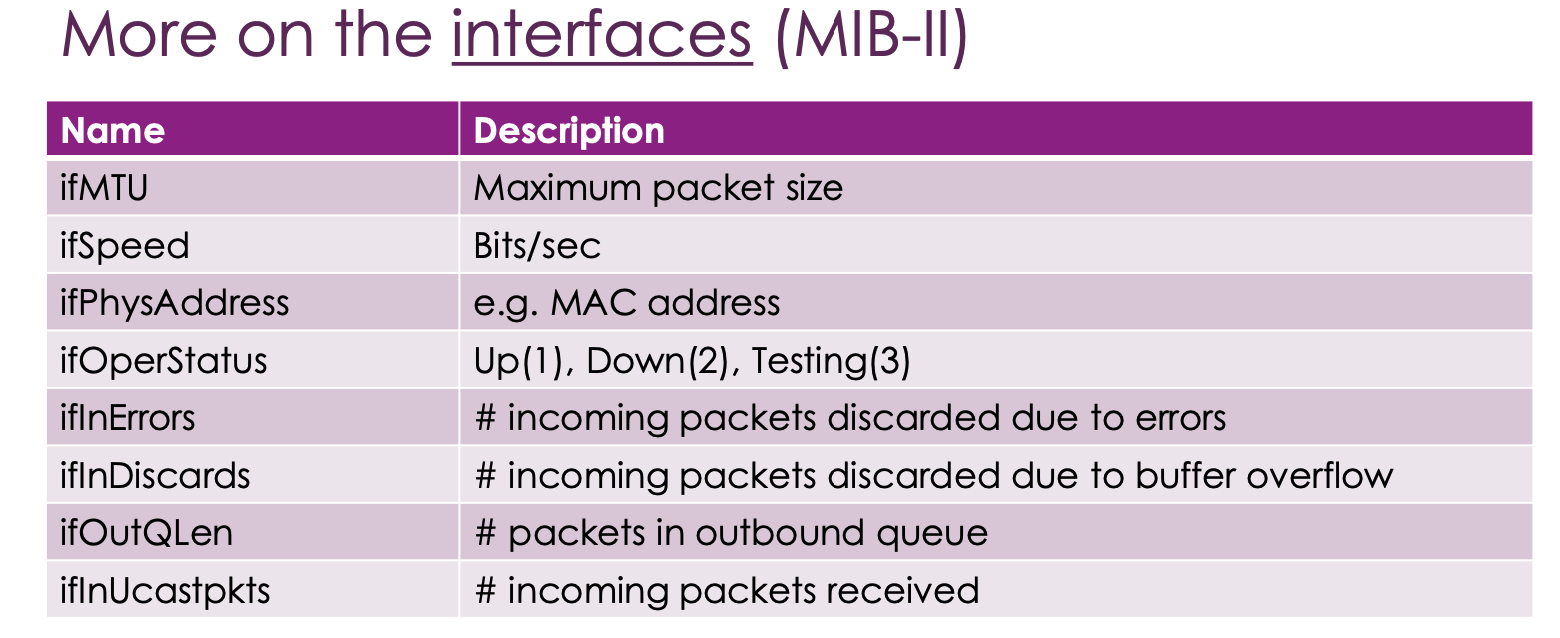
Lexicographical order of OID Tree - 곱집합에 위지하는 부분 순서
즉 밑의 사진의 경우 Interface 와 ipAddress 사이의 숫자 부분을 말함.
Get 요청은 SNMP에서 굉장히 구체적인 명령어로, MIB 에 존재하고 있음을 알아야 함
따라서 Get으로 비슷한 관련 데이터를 읽기 위해서는 모두 각각의 위치를 알고 있어야 함 (행열 모두).
The SNMP GETNEXT operation is similar to the SNMP GET operation. The GETNEXT operation retrieves the value of the next OID in the tree. The GETNEXT operation is particularly useful for retrieving the table data and also for variables that cannot be specifically named. It is used for traversing the MIB tree.
Tunnel (=encapsulation) IP packets across the internet (IP in IP)
물론 단순한 터널링은 아무런 보호성도 가지고 있지 않음, 그냥 헤더만 하나더 붙임
No confidentiality, authentication, integrity
IP Security 을 이용해서 VPN connection 을 secure 하게 establishment 하는것
네트워크 레벨에서의 암호화
종단간의 (호스트, 라우터) 키 공유
패킷의 캡슐화및 보호화
VPN Endpoints 는 위에서 말했든 호스트, 라우터 두개의 종단간에 가능하다
Tunnel Mode: Router and Router (with forwarding)
모든 서브넷을 투명하게 연결시킴 (하나처럼 보이게 터널로)
라우터간 연결되었으니 서브넷 두개가 하나처럼 보이는것.
NAT friendly (라우터가 관리 터널끝이니까, 요즘 NAT은 라우터에 같이 있음)
New IP header는 라우터의 주소이다 - 종단 라우터에 도착하면 (터널끝), 패킷 풀어서 해당 기기에 보내주는것 (즉 터널 밖으로 나오지 않는 이상 어디로 가는지 모름)
Transport Mode: Host and Host (no forwarding)
다른 포맷으로 오직 IP payload만 암호화 한다 (라우터 합침을 통한 서브넷간의 통합이 아닌 두 호스트간의 LAN 같이 사용하는거)
이로 인해 트래픽이 어디서 어디로 가는지 경로가 유출됨 (최종 목족지)
문제는 해당 아이피가 NAT 에서 사용되는 경우 사실과 다를수 있기 때문에, 이를 위한 PSK를 통한 인증이 필요하다. 그렇기 떄문에 NAT challenge
내가 헷갈려한 것은, VPN 서버를 이용할 경우 (나라 장벽떄문에) 이게 어떻게 진행되냐는건데,
VPN을 통해 나라 장벽을 우회하려면, 해당 VPN 서버에 대해 터널 모드를 만들어서, VPN 서버에 도착하면 내 원래 목적지 주소를 알려주고 거기에서 다시 목적지로 향하는것 (해당 VPN 서버에서는 무슨 모드이건 그건 이제 선택사항임).
장벽 우회같은 이유가 아니면, 그냥 공공망 바로 터널이던 전송이던 알아서 쓰면됨.
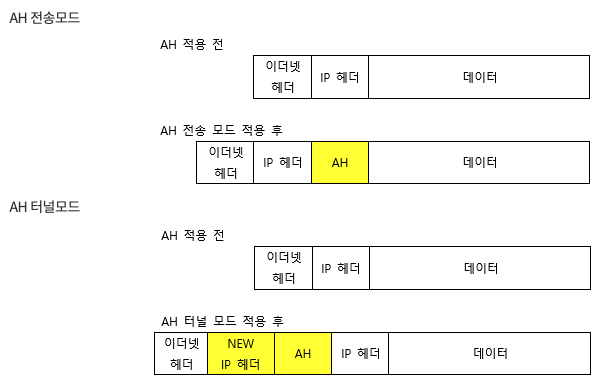
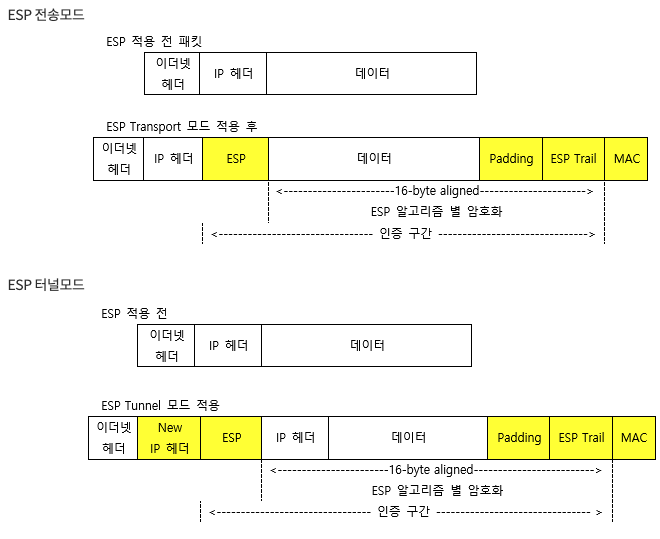
AH 는 기밀성을 보장하지 않음, ESP는 다 보장함.
ESP(Encapsulating Security Payload)
새로운 데이터 IP Packet을 만들고 기존 IP Packet을 Data Payload에 넣어 감싸는 방식
AH (인증) 가 가진 무결성과, 인증도 제공하고 추가적으로 대칭키 암호화 (PSK) 를 통해 기밀성(Confidentiality) 제공
Tunnel Mode
즉 위의 터널 모드는 애초의 목적지인 IP header 까지 암호화 시키니, 미아가 되지 않도록 터널링을 담당하는 장비 (라우터) 의 아이피를 적어서 보낸다. 즉 라우터간 (터널) 동안에 기밀성이 보장된다 (물론 이 라우터로 가고 있다는 트래픽 경로의 경우 유출이 되니 - 어느정도의 기밀성이 보장된다 가 알맞다).
따라서 해킹을 위해서는 A, B 혹은 라우터 장비의 물리적 회선망 (A나 B로 향하는)에서나 가능하다.
터널내에서는 esp가 존재하므로 암호화에 따라 해킹이 매우 힘들다
Transport Mode
만약 해당 네트워크가 NAT를 이용하면, 수신자 측에서 검증시 인증에 실패 할 수 있기에, PSK를 사용하여 서로 인증을 해야함 (그래서 NAT Challenge )
또한 전송 모드는 단대단 간의 연결 (TCP 처럼) 을 보호해주기에 Transport layer의 보안으로도 사용될수 있다.
터널 모드와 다르게 전송 모드는 패킷 페이로드만 보호해주며, 이로인해 경로 유출이 일어난다.
아까 위에서 말한 헷갈린점은 VPN 사설 서버를 이용하는 경우에 터널 모드를 사용하니 결국 어디로 가는지 모름 공용망 시점에선.
VPN 주의점
이 종단 라우터 또한 반드시 해당 기기에 가장 가까운 라우터라는 법은 없음. 단지 그냥 터널링을 끝내는 라우터에 불과함 (즉 해당 라우터에서 해당 기기까지 가는데 다른 라우터를 지나갈수 있음)
따라서 end-point에서부터는 누가 누구에게 이야기 하는지 알수 있음
보통 아이피는 위치에 따라 지정된다
결국 터널링이 끝나는 순간 보호되지 않은 트래픽이 된다 → 여전히 보안의 위험성 존재
따라서 이러한 상황을 더 나아지게 하기 위해 더 많은 터널링을 하는식으로 보완한다.
Onion routing = onion encryption
랜덤하게 세가지 노드를 선택한다 - 가드/미들/출구
클라이언트는 해당 세가지 노드에 대한 public keys를 가지고 각각에 대해 세션키를 만든다.
클라이언트를 각각의 세션키를 이용해 모든 패킷들을 암호화 한다 + 서버가 필요한것 포함
물론 이 방식은 세가지의 중간 노드만 정확히 지정해 둔거고, 이 노드를 방문하는 라우팅 알고리즘은 공용망에 맡긴다 (알아서 데려가줄텐데, 이 세 가드 미들 출구만 정확히 지나가면됨)
따라서 이는 MPLS (multi protocol label switching) 과는 다음과 같은 이유로 다르다
MPLS는
미리 모든 경로를 지정해둠 (onion 의 경우 세개만 지정)
패킷들은 토큰으로 레이블되어 있음 (onion은 세션키로)
경로중 하나만 죽어도 다 실패함 (onion은 맨끝만 죽으면 실패한다 - 주는사람 or 받는사람)
Physical Security
Device Security
스위치와 라우터는 물리적이고 가상적인 인터페이스를 가지고 있음
원격 엑세스
SNMP agents (HTTP)
OS (Telnet ssh)
Port monitors and mirrors
다른 포트에 대한 트래픽을 반영하며, 바깥에서는 알수 없는 정보
물리적 엑세스
인터페이스 재정렬 (denial) 혹은 공격
케이블 절단, 방해
칩 레벨 스누핑
Copper Security
여기서 말하는 보안은 이를 이용한 데이터 보안이 아닌, 말 그대로 코퍼에 대한 보안임
attenuation등이 원래 발생하는 라인이기에, 문제가 생겼는지 발견하기가 쉽지 않음
자르기도 편하며, 누군가 케이블 자체를 (라인이던 쉴드던) 건드리면 denial of service (noise, antenna, energy loss) 등이 발생함
Fiber Security
코퍼에 비해서는 발견하기가 쉬운데 케이블 특성상 loss 가 발생하기 어렵기 때문
물론 선 절단이던 tapping (금가거나 등등) 은 코퍼와 마찬가지로 쉽게 발생한다. 그래서 NSA에서 해저 밑바닥에 깔아둠.
Wireless Security
무선은 특성상 브로드케스트 이기때문에
좁은 beam 안테나와 짧은 wavelength 가 도움이 된다
빌런들이 듣고있으며, 적극적으로 intrude 할 수 있음
물론 access 에 관한 말이고, 해당 패킷이 암호화가 잘 되어있는거는 다른 이야기
802.11
기기와 wifi 사이 (무선연결) 의 payload에 대한 암호화를 책임지고, 해당 데이터가 와이파이 라우터에 성공적으로 전달되면, 해당 암호화를 풀고 선 (물리적)을 이용해서 목적지로 전달한다
즉 무선 기기간의 암호를 책임지는 프로토콜임
Wifi Network Keys
Layer 2
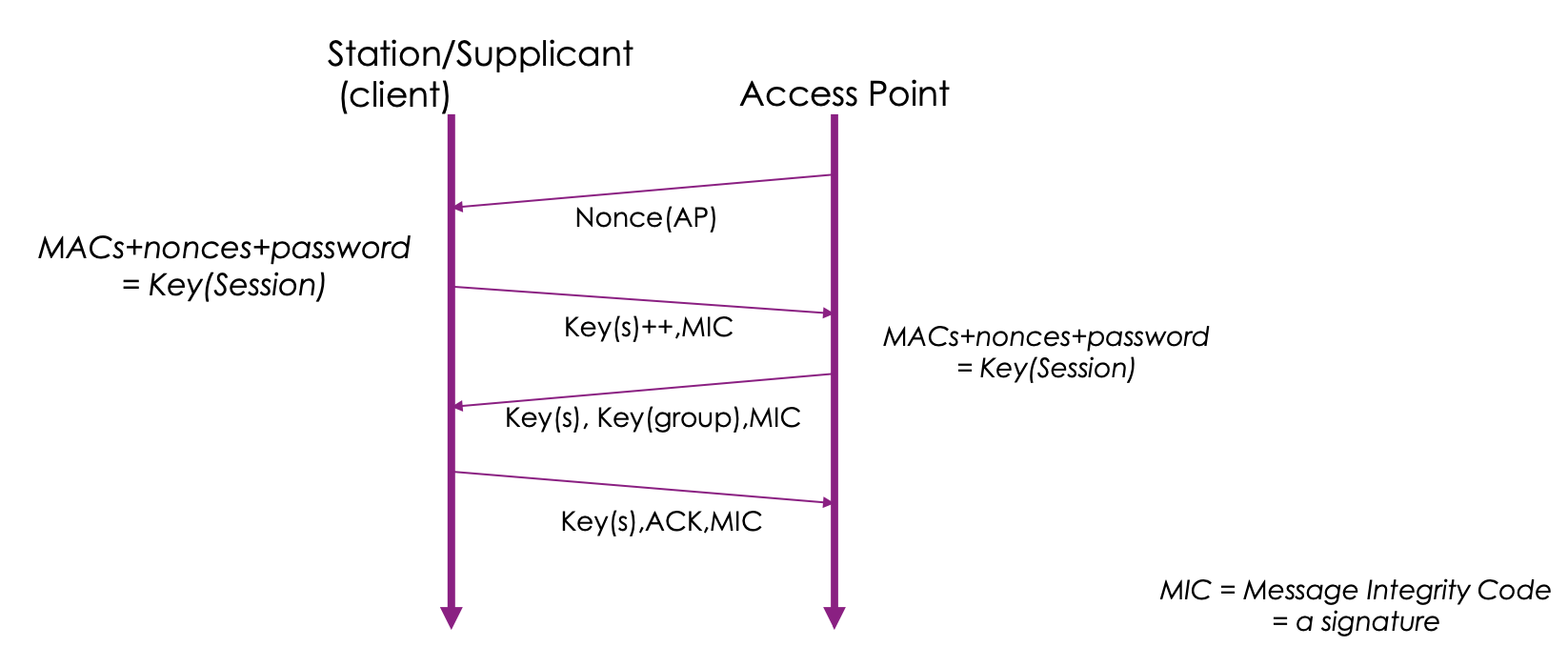
클라이언트가 AP에게 인증한다
클라이언트가 AP에게 요청하면 AP가 수락하고, 등록후에 더 많은 키를 나누어준다
각각 SSID password (pre shared key -PSK)로 부터 얻은 공유 세션키를 계산한다.
이 공유 세션키를 이용해서 PMK, GMK 를 생성하고 이 마스터 키들이 이후의 PTK, GTK 유도하기 위해 사용되는 보조키 역할을 한다.
여기서 만들어진 Pairwise Transient Key (PTK) 를 무선구간 암호화를 위해 사용한다
AP to Clients (broadcast/multicast)
Group Temporal Key 를 이용하는데 마찬가지로 무선구간 암호화를 위해 사용한다.
PTK와 다르게 브로드캐스트, 멀티캐스트용이다.
1 2 3 4 5 6 7 8 9
구분 - 4-Way Handshake . Pairwise Key,Group Key 생성을 위함 - Group Key Handshake . 이전에 4-Way Handshake을 통해서, PTK 및 GTK를 확보한 STA에게, Multicast/Broadcast용 데이터 암호화를 위한 GTK를 분배하기 위한 2-Way Handshake 임 . 사실상, 위 4-Way Handshake에서 끝에 있는 2번의 메세지 교환 단계와 동일함 - PeerKey Handshake - TDLS PeerKey Handshake
원래는 Station - AP - Authentication server 로 이루어져야 한다.
AP 가 클라이언트에게 제공 가능한 서비스들을 알려줌
먼저 서로 인증을 위해 EAP 를 이용해서 메세지를 전달한다. 클라이언트와 무선은 EAPOL을 통하고, 무선과 인증서버는 RADIUS라는 프로토콜을 이용해 인증한다. 이 과정중 마스터 세션 키를 생성한다
마스터 세션키는 클라이언트와 인증 서버만 가지고 있는데, 이를 이용하여 PMK를 만들고, 인증서버가 이를 AP 에게 보낸다.
Lightweight: 기기의 성능에 영향 가지 않도록 (no interference on device)
No rates, no calculation, no history
No absolute clock: 정해진 클록이 존재하지 않음 (즉 다양한 클록 스피드로 통화가능)
단지 Counters/gauage, Time since start-up, strings/identifiers 만 존재
시간은 1/100 sec 단위이다
command/control 은 변수 셋팅을 통해 이루어진다
Operate when under stress: 부하가 걸린 상태에서도 작동 가능하게
뭐가 문제인지 알아내고 고칠수 있도록 도움을 주기위해서
Scale to large num of device: 글로벌 네이밍, delegated, 제조사-독립적, 추가적
즉 누가 만들고 이런거를 떠나서 다양하게 많은 수의 기기들을 포함할수 있도록
Provide both queries/response and command/control: 질문/답변, 명령/조종 모두 가능하게
security and upgrade later
말 그대로 간단한 네트워크 조절 프로토콜로, 네트워크에 수많이 존재하는 모든 기기들 (무슨 타입 종류건 상관없이) 에 대해 문제가 생기면 고칠수 있고, 해당 기기와 교류 할 수 있는 (질문답변…) 것을 제공하는 것.
이는 곧 해당 네트워크 기기에 문제가 생기면 경로를 탐색할 필요 없이 걔만 고치면됨.
따라서 부담을 줄이기 위해 UDP 161 (서버), 162 (에이전트) 포트를 사용한다.
여기서 에이전트는 (서버) 클라이언트는 (매니저) 이다.
SNMP
어플리케이션 프레임워크
네트워크 리소스의 관리 및 모니터링 담당
SNMP 구성요소로는 다음과 같다
SNMP agents: 각 기기에 존재하는 소프트웨어
설정및 데이터베이스 상태 관리
Proxies: 혹은 non-SNMP (IoT 등등 얘를 거쳐야만 그 기기랑 대화 가능) 기기와 대화 가능한 프록시 역할해주는 agent
Proxy agent 와 Proxied Agent가 존재한다.
SNMP managers: agent와 대화하는 어플리케이션
해당 에이전트의 데이터베이스를 쿼리 혹은 수정하는 역할
또한 네트워크 장치의 이벤트를 인식함 (에이전트가 전송함)
Network management system 의 일부이다
Management Information Bases (MIB)
다양한 데이터 베이스 구조가 존재함
Structure of management Information (SMI) 는 MIB에 존재하는 관련된 오브젝트를 정의함
즉 관리 장치에 대한 정보가 집합되어 있는 데이터베이스
SNMP protocol
여러 버전 존재함 1, 2, 3
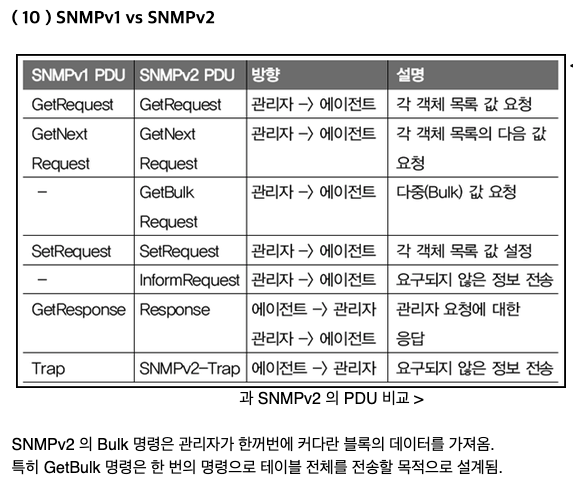
SNMP Messages
SNMP/UDP is connectionless
request ID 를 이용하여 세션을 유지한다
SNMP messages use “protocol data units” - PDUs
다양한 버전의 SNMP는 같은 PDU를 다른 메세지로 사용한다 (그래서 지금 문제되고 있음)
또한 각 다양한 메세지 form은 이 PDU의 전체 맥락에서 조금씩 바꿔서 사용하는것
Trap : 에이전트가 무슨일이 있다고 (이벤트) 매니저에게 알리는것 (비동기적 - 일방적으로 알리는것)
링크 다운/업, 스타트 콜드/웜 (급작스러운 재시작 혹은 예정된 재시작)
인증실패, egpNeighbourLoss (링크는 켜졌는데 이웃이 사라짐)
과 같은 6가지 기본 상태와 벤더에 따른 여러 trap 상태가 존재한다 2^32 개수까지 존재 가능
SNMP Community - 어디 소속인지
SNMP1 의 경우
특정 변수 셋트에 대해 특정한 액세스를 정의함
read-write, read only, none 등의 세가지 타입이 있음
각각의 SNMP 는 community name 이
패스워드 같고, 암호화 되어 있지 않음
이게 무슨말이냐면 read-only: Public, read-write: Private 가 비밀번호임 ㅋㅋㅋㅋ
따라서 보안적으로 하나하나 새로 설정해 주지 않으면 위가 기본 비밀번호
에이전트가 특정 IP 주소를 저장해서 해당 아이피의 매니저만 데이터베이스 건드릴수 있도록 하는것도 가능
SNMP Versions
v2c
벌크 기능 추가, 매니저간 대화 기능 추가, TCP 기능 추가, 64 비트 카운터 추가
v3
보안 추가 (v2c 의 기능은 없음)
보통 다들 v1,2,3 모두 지원함
SNMP Security
v1 - community string 을 인증 방법으로 이용함 (아까 그 public, private) - 암호화 전무
v2 - 위 문제 고쳤어야 하는데 안고침 ㅋㅋ
v3
Integrity - 패킷이 tampered 되지 않음을 분명히 함
authentication - 정당한 소스로부터 해당 메세지가 왔음을 분명히 함
privacy - 메세지가 읽히지 않음을 분명히 함
다향한 보안 단계를 가지고 있으며, 단계에 따라 접근 권한이 다르다
noAuthNoPriv: 유저네임 매칭을 통한 인증 방법
authNoPriv: 메세지 digest를 이용한 인증 방법
authPriv: message digest 를 통한 인증과 암호화 사용
MIB 안에 값들이 저장되어 있는데, SMI 를 통해 정보가 수집된다 (통계 자료 등등)
예를 들어 값들이 어느 디렉토리 안에 저장되면, 해당 디렉토리까지 가는데 SMI 을 통해서 지나간다. 이 지나가는 와중에 해당 정보들을 structure 하게 수집해서, 몇개의 패킷이 지나갔는지, 지금 전송율이 어떤지 등등을 모집하는것이 바로 Structure for Management Information (SMI) 이다.
물론 에이전트가 직접 계산하는게 아니라, 단지 자료를 모음으로써 위의 계산들을 가능하게 해주는 형식
Counter / Gauages
위 두가지가 현재를 가장 잘 알려줌
Counter: 현 인터페이스에 존재하는 패킷들 (can wrap)
Gauge: 메모리/디스크 공간 (0부터 맥시멈까지)
에이전트는, 다시 말하지만, history를 가지지 않으며 계산도 하지 않음
단지 켜진 순간부터 얼마나 시간이 지났나만 알고 있음
따라서 매니저는 계속해서 물어보면 다음과 같은 가정들을 세워야함
Counter 가 바뀌지 않았다 (패킷 수가 똑같다) → 이전과 같은 상태
Gauge가 바뀌지 않았다 → 이전과 같을수도 다를수도 있다 (메모리/디스크 소비량은 같은데 값은 바뀔수 있으니까)
MIB 디자이너는 해당 정보를 위해 여러 필드/타입이 필요 할 수 있다 (즉 어느 정보를 유추하기 위해서는 여러가지 필드들을 참조해야 할 수 있다)
ASN
데이터들은 ASN 이라는 Abstract Syntax Notation One 규격에 따라서 저장된다
Q: On congestion, where does that actually happen on a network path?
A: 어느 특정 아웃바운드 연결/경료에 대해 너무 많은 트래픽이 올시에 라우터의 버퍼에서 발생함
특정 아웃바운드 연결/경로가 중요하다. 각각의 연결/경로는 다른 버퍼를 가질수 있으니까.
라우터 버퍼가 가득참 → 패킷이 드롭됨 → 손실 발생
라우터 버퍼가 거의 가득참 → 패킷이 보내지는데 시간 걸림 → 지연 발생
Q: What’s the difference between ‘throughput’ and ‘goodput’?
A:
throughput은 통과하는 데이터의 볼륨 (크기)를 말한다 (그게 무슨 데이터간에).
Goodput은 통과하는 “새로운” 데이터의 볼륨을 칭한다 (이게 어플리케이션에서 말하는 “effective transmission rate” 과 관계되어 있음). 즉 재전송이 아닌 새로운 데이터의 볼륨.
Q: Why do we get a collapse in goodput as we approach congestion?
A: 혼잡해질수록 새로운 데이터가 통과하는 볼륨은 줄어들고 대신 retransmission 과 이에 대한 requests만 늘어날테니까.
Q: Why does TCP traffic (often) have a sawtooth pattern?
A: 네트워크를 정찰 (probe) 하면서 혼잡을 일으키지 않을떄 까지 점점 증가하다가, 혼잡이 발생하자마자 바로 줄여버리니까
Additive Increase, Multiplicative Decrease (AIMD)
Q: How can we detect congestion? (3 ways, at least)
A:
패킷 손실 증가: 명확하게 혼잡 감지, 대신 혼잡이 생긴후에 감지
패킷 지연 증가: 혼잡이 생김을 예상 (추론), 혼잡을 미리 감지함
ECN: 혼잡을 감지 (라우터가 알랴줌), 대신 라우터와 호스트간에 협조 필요
IP header에 플래그를 설정한다.
Q: How does Selective Acknowledgement (SACK) greatly help TCP performance?
A:
송신자에게 수신가자 무엇을 받았는지 정확하게 알려줌으로써 놓친 부분만 다시 보내게 되니 보내는 양이 줄어들고 성능에 도움이됨
Q: What’s the difference between ‘fairness’ and ‘efficiency’ in networking terms?
A: 공평성은 네트워크 접근에 공평하게 (비슷한 송신율) 처리되는지. 효율성은 전체적인 네트워크를 보면서 가능한 최대한 성능을 끌어 올리고 있는지
Q: TCP has (at least) 3 types of “windows” for managing the transmission of segments (over packets). Explain their key roles: SendWindow, ReceiveWindow, and CongestionWindow
A:
SendWindow: 네트워크 효율성을 최대한 높이기 위해서
RecvWindow: 송수신자 간의 성능 밸런싱을 위해서 (수신자가 송신자보다 빠르면 문제가 발생함)
CongestionWindow: 송수신자간의 네트워크의 capacity 를 (거의 즉각적으로) 계산해서 흐름간의 공평성을 보장함. 혼잡 윈도우는 그냥 전송가능한 버퍼크기라고 생각하면 되는데 송신자는 최대 자신의 혼잡윈도우 크기만큼 트래픽을 전송가능하다. 이 혼잡윈도우는 네트워크의 혼잡도에 따라 커지기도하고 작아지기도 한다.
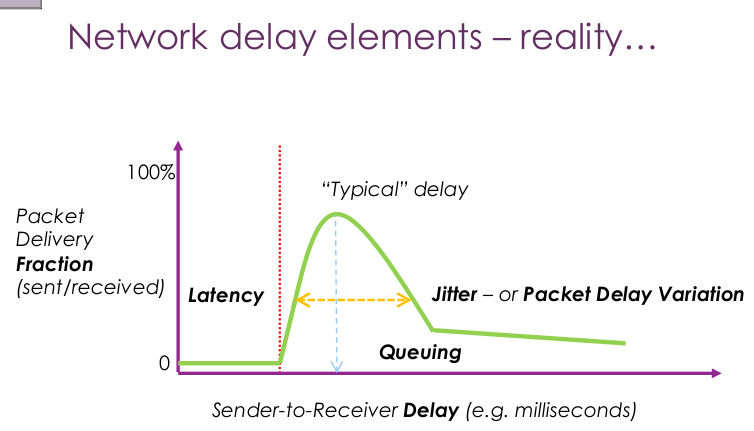
A_1: sender/receiver transmission 딜레이로 피할수 없는 딜레이 이다.
Q_2: What causes the long tail at the far right?
A_2: 도착하기 까지 여러 구간에서 다양한 이유로 멈춰진 패킷들의 도착
Q_3: What would cause jitter to become very large?
A_3: 지터는 다양한 넓이의/종류의 딜레이를 나타낸다. 아마도 이와 같은 경우는 중간에 경로가 다양하게 바뀌었거나, 해당 경로의 라우터들의 load가 갑자기 바빠지거나 한듯하다
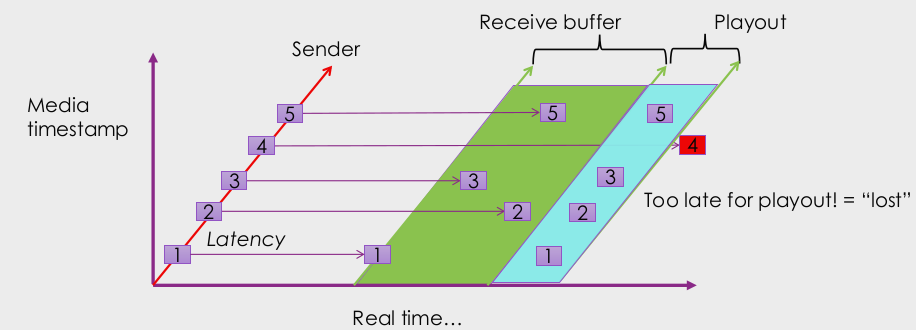
Q: Why is packet 4 not able to be played out, since it was received? How could we fix that? What problem does that cause?
A: 수신 버퍼의 길이가 패킷 4를 수신하기에 너무 짧았음. 이를 고치기 위해 버퍼의 길이를 더 늘릴수 있지만, 그렇게 하면 송신과 플레이 시간의 지연이 더 커질것임. 따라서 실시간이라 부르기 애매해진다 (내가 말하고 몇초뒤에 상대방이 답한다던가 하는것).
Q: Why is retransmission (except in multicast) generally a bad idea? Why is it ok in multicast?
A: 잃어버린 패킷을 감지하고, 재요청하고 (그 잃어버린 패킷을 아직 가지고 있길 희망하면서), 패킷을 받는과정이 너무 오래걸리기 때문. 물론 재요청해서 바로 받는다는 보장도 없다. 멀티캐스트에서는 retransmission 해주는 위치가 가까울수 있어서 지연이 줄어들기 떄문.
Q: Why are the performance problems reduced in streaming applications?
A: 문제는 여전히 존재하나, 이는 단방향 트래픽이기 때문에 딜레이를 알아차리지 못한다 (화상 통화가 아닌 트위치 같은거 말하는거). 이 뜻은 내가 받은 버퍼의 크기를 키워서 안정적인 (reliable) 프토토콜을 사용 가능하다는것. → 내가 트위치 볼때 안끊기기만 하면 되니까 이에 맞춰 버퍼만 키우면됨
Q: What are the main network and device issues for IoT? Why is it different to other devices connecting to the internet?
A: Scale, Power, Network, Timeliness, Reliability → 해당 자료 읽어볼것.
Q: As an application model, how is PubSub different to Client/Server? Why is it better suited to large-scale IoT applications?
A: 클라이언트와 서버는 1:1 관계를 가진다 반면에 PubSub은 데이터 진원지 (소스)와 publishing 하는것이 나뉘어져 있기 때문에 서버/브로커를 통해 구독자들이 정보를 얻을수 있다. 또한 확장성과 관련해서 n 개의 생산자와 m의 소비자들이 있다면, n*m 대신 n+m의 직접적인 관계를 유지 할 수 있다 (중간에 브로커 하나). 또한 이러한 관계는 오직 해당 토픽에 관심있는 구독자들에게만 정보를 push 하기 때문에 reducing load for producers and brokers.
Q: Why are MQTT packets so compact and simple? (compared to HTTP say)
A: 성능과 부하를 위해서 이다. 짧은 메세지는 대역폭을 거의 소모하지 않고 간단함은 패킷 구성에 관한 CPU 소모량을 줄일수 있다.
Q: Why does MQTT offer multiple levels of QoS (quality of service)? Why is there separate, potentially different, QoS on both sides of the broker (producer->broker, broker->consumer)?
A: 상황에 따라 해당 메세지가 반드시 ensure 해야 할지, 혹은 가끔 업데이트로 충분한지, 혹은 메세지를 놓치더라도 다음까지 기다릴수 있는지 등 요구조건이 다르기 때문이다. 해당 소비자가 그 정보에 대한 중요도가 다르기 때문에, 중요하게 여기는 소비자는 높은 QoS를 이용할것이고 아니면 낮은 레벨을 사용할 것이다. 이로 인하여 데이터 소모량에 대한 유연성을 가질수 있다 (QoS 레벨에 따라 데이터 필요량이 다르니까 - 커뮤니케이션 횟수가 다름)
QoS 0 을 선호하는 사람들은 굳이 복잡한 QoS 2 안 써도 되니까.
Q: In what circumstances is it useful for a server to ‘retain’ an MQTT-published message?
A: 소스가 가끔 메세지를 주던지, 소비자가 언제던지 들어올수 있던지, 혹은 비안정적으로 연결되어 있던지 할때 좋음. 서버에 리테인 함으로써 위와 같은 상황에 현재 which state (메세지) 가 있는지 빠르게 배울수 있음. 즉 서버가 정보를 가지고 있으면 소비자가 재부팅하고 (그 사이에 정보를 못받았던, 정보가 초기화 되서 아무것도 모른다던지) 다시 들어와도 빠르게 “응 지금 메세지 이 상태임” 하고 알려줄수 있는거.
Q: What is the ‘root’ of the Domain Name System? i.e. what is at the very top?
A: “,” is the root of the DNS. It is to refer the root DNS server
Let’s look at some Fully Qualified Domain Names (FQDN) with different Top Level Domains (TLD). Consider: www.anu.edu.au. and www.gov.au
Q: Which part is the ‘genericTLD’ (gTLD)?
A: Edu, gov.
Q: Which part is the ‘countrycodeTLD’ (ccTLD)?
A: au 다만 미국의 경우 us 를 사용하지 않음.
Q: Which part is the hostname?
A: www 가 이에 해당한다. DNS에서 해당 주소 (www.anu.edu.au) 의 A가 이 호스트 주소에 해당된다.
호스트 네임은 종단 기기에 지정된 이름 (DNS를 통해 식별)
도메인 네임은 네트워크에 지정된 이름 (네트워크에 연결되야함)
Q: In the case of cbs.anu.edu.au is the ‘cbs’ a hostname or a domain name, or both? How can you tell the difference? What’s the benefit/downsides of this approach?
Q: Packets with a source IP address of 0.0.0.0 is used (by DHCP) to signify what? What does the address mean to the Operating System? Why do we use it that way?
A: 이는 해당 호스트가 현재 아이피 주소를 모르고 있은 상태이고, 이로 인하여 해당 호스트와 연락하기 위해서는 브로드캐스트를 이용 할 수 밖에 없다. 운영체제에서 0.0.0.0 은 “모든 인터페이스” 를 뜻하며 모든 인터페이스들에게 보내지고 모든 인터페이스는 이 메세지를 듣는다.
Q: Why does DHCP have both discover/offer AND request/acknowledge? Why not just request/acknowledge?
A: DHCP의 아이피 주소 할당은 임시 (lease)이며 확인되어야 하기 때문이다. 또한 만약 여러기기가 동시에 같은 아이피 주소를 요청할 경우를 대비해야 하기 때문이다. 따라서 서버와 클라이언트는 해당 아이피가 고유하다는것을 알기위한 확인 절차가 필요하다.
Server Discovery
IP lease offer
IP Request
IP lease ACK
Q: Give some examples where and why a single IP address may be used by multiple (DNS) names? What about examples where a single name may resolve to multiple addresses?
A: 예를 들어 같은 아이피 주소를 가지고 있는 웹서버와 메일 서버 같은 다른 서비스를 제공하는 경우. 이는 결국 일어날 서비스의 이동에 대한 유연성을 준다. 한 이름에 대한 여러가지 주소를 가지는 경우는 옵션과 같이 사용되는데 첫번째가 사용 불가하면 두번째가 사용된다던가, 혹은 이로 인해 로드 밸런싱도 가능하다.
Q: In DNS, how are Zones and Domains different?
A: 도메인의 경우 DNS 의 일정 부분을 이야기한다. 예를 들어 anu.edu.au 의 경우 도메인이고 (au, edu, anu 순으로 내려온다), 이 이하의 다양한 부서와 서버들과 같은 여러가지를 묶어서 zone 이라고 표한다.
Q: Why are DNS delegations legally important?
A: 도메인 네임은 보통 그 해당 entity의 법적 이름과 연결된다. 즉 구글이라는 사업체가 있는데 이를 모방해서 google.com 등을 사용한다면? 이는 곧 사기와 trademark infringement 와 같은 법을 어기는것.
Q: What’s the difference (and for/against) using Iterative or Recursive DNS queries?
A: Interative 는 내 스스로가 정보를 받고 다음에 물어보고 받고 물어보고 하는형식 Recursive는 네임서버에게 물어보면 걔가 알아서 물어물어 정보 가져다 주는것. 당연히 Recursive가 편하지만 더 느림.