
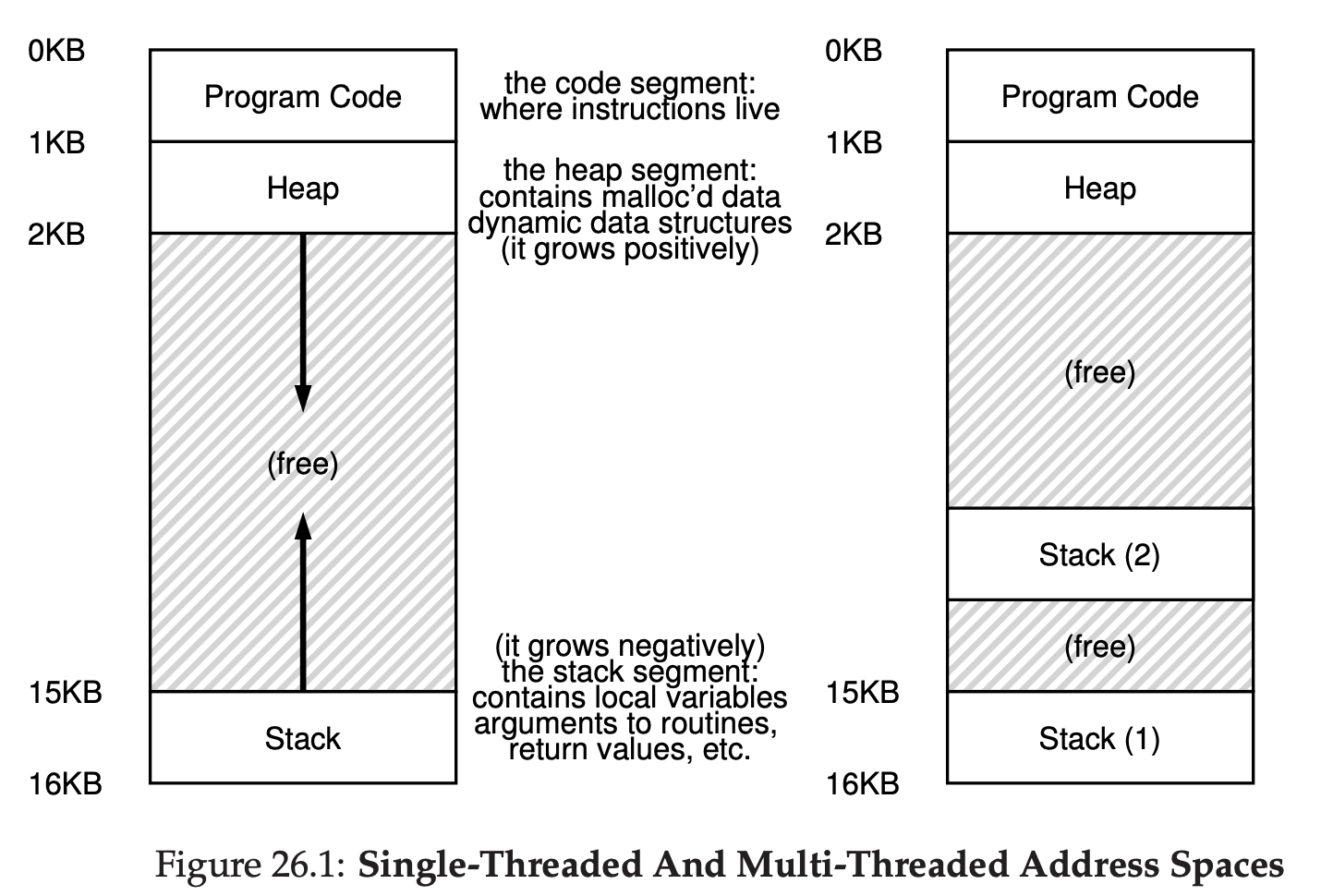


Very Simple File System (VSFS)
This is pure software that allows to study/experience the simplified version of UNIX file system.
- Key Question: How can we struct simple file system? What data structure is needed on top of disk, and how can it track certain data?
Approach
- Data Structure: What kind of data structure is needed so that file system can handle its data and metadata?
- Access Method: How system calls are related to the data structure of file system? How efficient are they???
Overall Organization
Disk block - normally 4KB.
Data Region - Disk space where user data exist.
Allocation Structure: Indicate whether the blocks are being used or not.
- free list: Manages non-used blocks in a linked list form. Hence inode only remembers the head.
Disk Space (assume 64 blocks):
- Metadata: Information such as data blocks (data region), size of file, owner, access, access change time…. –> usually saved in data structure called inode.
- Inode Table: disk space for saving inodes; saved in array format.
- Inode is usually size between 128 ~ 256 bytes -> 16 inodes in 4KB block, 80 inodes in the file system (as we use 5 * 4KB blocks).
- Superblock: Contain information about the entire file system; how many inodes, data blocks we have, where the inode table starts…
- When we say “file system is brokeb” means superblock is damaged.
- Usually, file system duplicates superblock for backups.
OS Reads superblock, initialize file system elements, paste each partition to system tree when mount the file system -> by doing so, can know the location of required data structure when access the file.
File Organization: inode
Inode has:
- File type; normal, directory…
- Size, block allocation, protected info (owner, access), time.
- Location within the disk (as like ptr).
And these are called metadata.
Important to consider within inode structure is way of expressing the data block location. Simple method could be include multipe direct pointer within the inode. Each pointer points on disk block.
-> Has file size limitation: Size is limited to num of pointers * block size.
Multi Level Index
- To support bigger file, needed to add one more data structure; indirect pointer.
- Indirect pointer does not point data block. It points the pointer that points the data block.
- Inode has fixed number of direct pointer (i.e. 12) and one indirect pointer.
- Indirect block is allocated to a big file (within disk data block region), and inode indirect pointer points this indirect block.

If bigger file wanted, then use double indirect pointer which points indirect pointer. If bigger then triple indirect pointer…
All together, disk block forms one-sided tree -> multi level index.
Extent:
- consists of disk pointer and length of block -> means it required continuous disk space for each extent.
- Therefore, use multipe extents to overcome this limitation which brings another limitation: metada gets bigger.
Linux use ext2, ext3 (multi level index), some OS use extent.
Reason the tree (MLI) is biased -> most files are small
If most files are small, needs to construct file system to read small files fast -> vsfs has inode that can read first (usually) 12 blocks fast (the direct pointers).
Directory Organization
vsfs direcotry (like the other file system) has (entry name, inum).
In the directory data block, it has: inum | reclen | strlen | name.
- dot: current directory
- dot-dot: parent directory
- inmum = 0: unlinked; deleted -> needs len in case create another object in the gap later.
We should also note again that this simple linear list of directory entries is not the only way to store such information. As before, any data structure is possible.
Free space maintenance
File system must be able to track which inodes and data blocks are free or not -> to allocate new space for file/directory -> free space management.
vsfs uses two bitmaps.
- File creation:
- file system searches inode bitmap and allocates the empty inode to the file.
- Note the inode now is being used, and update disk bitmap accordingly.
- Similar steps for data block allocation.
- Needs to consider…
- ext2,ext3: If possible, find sequence of blocks so that future additional allocation request can have contiguous on the disk -> performance improving (called pre-allocation).
Access Paths: Reading and Writing
So far has learned how to save file and directory in the disk. Now need to understand how to read and write.
- Reading file from disk
- Open systemcall -> traverse the path name -> find inode to get basic information (metadata)
- Open Systemcall
- Traverse the path name
- Filesystem will read root inode first, which gets decided when the filesystem is mounted (usually 2).
- Filesystem extract pointer of a data block which contains root directory information.
- Read this directory information to find the target file.
- Find the block that has the inode of the target, and its inode.
- open() read the target’s inode number into the memory.
- Filesystem checks the acess authority.
- Get file descriptor from open file-table and return it to user.
- Read() - After open(), read comes
- By inode, know the location of the block in the disk, and read the block.
- Since it is the first read, will read the first block (if file offset is 0).
- After reading the file, record the time.
- Update offset of file descriptor (give by open-file-table).
- Next time, when read() happenes, it starts with the updated offset.
- Close: deallocate the file descriptor.
In summary:
- Read Root inode -> read Root data -> read foo inode -> read foo data -> read bar inode.
- read bar inode -> bar data[0] -> write bar inode (the offset).
- read bar inode -> bar data[1] -> write bar inode (the offset)….
As it could be checked, as the path gets longer, relevant inode and data must be read.
Hence, if the directory is big, then many data blocks must be read to find the targeted file.
- Write Disk
- Similar to read, it first uses open() and then write(), and deallocate the file descriptor.
- Unlike read, write may need block allocation which needs to decide which blocks to allocate and write on the disk -> required to update data structures of the disk (such as data bitmap and inode).
- Therofre, logically it makes 5 extra steps of I/O.
- One for read data bitmap, one for to write bitmap (to apply the change of states at the disk).
- Two for inode read and write (to apply the change of location at the disk).
- One for write the actual block.
- File creation - Very complicated and needs many I/O.
- One for reading inode bitmap (to find free inode), one to write on the inode bitmap (notice allocation)
- One for making new inode (reset), one for writing data block at directory (link inode name and parent name).
- Two for read and write directory inode (update)…..
Caching and buffering
For performance matter, most of filesystem cache frequently used blocks to DRAM.
- If no cahce: At least needs two reads per directory (directory inode and its data).
- Usually, fixed cache occupies 10% of the total memory -> static partitioning is wasteful.
- In the modern OS, use dynamic partitioning.
- United virtual memory pages and filesystem pages -> unified page cahce.
- Hence, can flexibly allocate between filesystem and virtual memory upon its need.
- Cached Read: It will cause many I/O for reading directory inode data, but follow up directory (children) will be cached, hence no extra I/O is needed.
- Cached Write: Since the changed data must be written back to the disk –> Called write buffering.
- By storing/saving the number of write-works,
- Multiple write processes can be batched with fewer I/Os.
- Can improve the performance by scheduling the multiple I/Os.
- Of course, it system crashes before saving, cached data will be gone.
- To avoid this situation, use fsync() for jobs that must be written right away,
- By storing/saving the number of write-works,
