




Reference : Introduction to Parallel Computing, Edition Second by Vipin Kumar et al
Basic Requirement
#1 Process Creation
Require a method for creating separate processes for execution on diff CPUs
Options
Static: num of processor is fixed during execution
Dynamic: num of processor fluctuates during execution
Both needs unique identification of each process.
// dynamic spawning number of processor by runtiem environment
mpirun -np 4 ./mpi_job //spawn 4 processors
// identify the num and the rank (unique identifier within the group
int MPI_Comm_size(MPI_Comm comm, int *size) //given by runtime env 4 in this case
int MPI_Comm_rank(MPI_Comm comm, int *rank) //identifier within the communicator (comm - handler)
#2 Data Transmission
Require a method for sending/receiving messages between processes.
1 | //data - usually a pointer and number of bytes |
Unix command
- fork - spawns an identical task to parent
- ssh - starts process on a remote machine
- exec - overwrites a process with a new process
- Socket - provides communication between machines
- shmget - provides communication within shared memory.
- xdr - provides data conversion between machines.
Message Transfer
Two buffers 1. Send,Receive buffer 2. System (local) buffer owned by MPI Lib among ranks)
Blocking meanst that the buffer is available for reuse. To reuse buffer, MPI can copy it to system buffer and empty so that it can be reused ( =MPI_Send() returns)
A blocking send can complete as soon as the msg is buffered (system) without having recv(). However, in some cases, buffering msg is expensive hence better to directly copy the data into receive buffer. That is why there are 4 modes.
Send Modes
- Standard Mode: If MPI decides to buffer, Send() can returns immediately without having corresponding Receive(). But if decided not for performace issue or lack of buffer size, it will stall (not return) until it has Receive(). Hence this mode is non-local as it may need receive() in case of not buffering the msg. MPI_Send()
- Buffered Mode: Same as standard mode except it will be buffered if no Receive(). Buffer allocation is user defined and if it is overflow —> error comes. MPI_Bsend()
- Synchronous Mode: Send() returns if Receive() posted and started to receive the msg. Hence the return states the Send() buffer is ready to be re-used and Receive() started taking the msg. If either blocking then it stalls. MPI_Ssend()
- Ready Mode: Can be started only if matching Receive() invoked. It does not tell if send buffer is ready nor receive(). However since it can be started if Receive(), correct implementation of this mode can be replaced by Standard and Sync mode without losing performance. MPI_Rsend.
Receive Modes
- Blocking Mode: receive returns only after it contains the data in its buffer —> does not imply whether or not it can complete before the matching send completes.
- Computation hasted untill the blocked buffer is freed —> waste resources as CPU remain Idle.
Non-Blocking
- Creats a request for communication for send/receive. Gets back a handle and terminates. It guaratees that the process is executed.
- For Sender: allows overlapping computation with communication
- For Receiver: allows overlapping a part of the communication overhead; copying the msg dircetly into the receiving address space in the application.
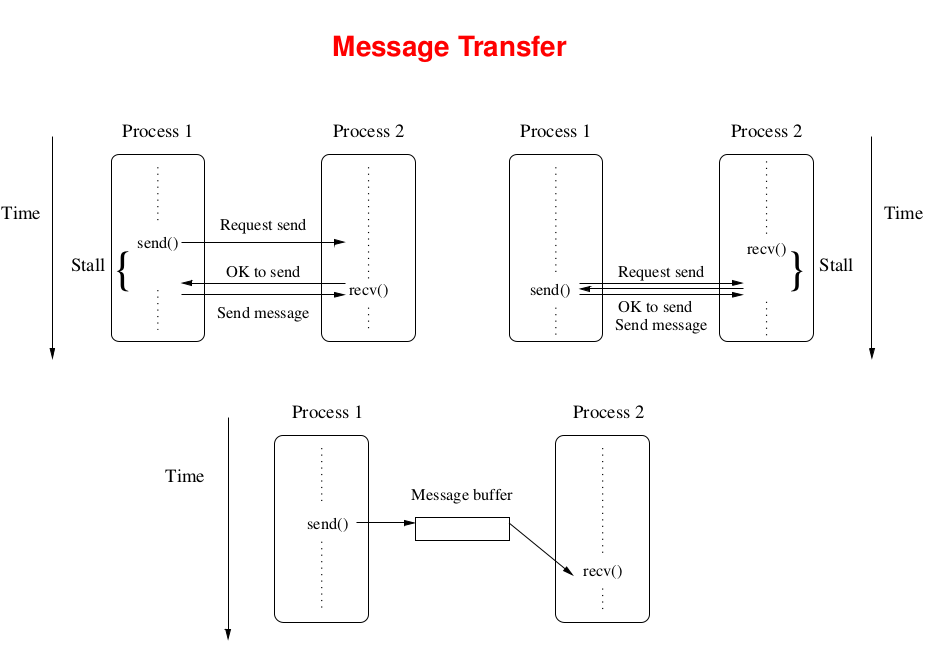
Synchronous: the send returns only when msg has been received.
- Request to send, receive the OK to send, send msg
Blocking: the send returns when it is safe to re-use the sending buffer (MPI is normally blocking method)
Locally blocking: returns after MPI copies the msg into a local buffer
Globally Blocking: returns when receiver has collected the msg (and hence has posted its receive call)
The receiver returns when msg has been received.
Non-blocking: the send returns immediately even though the data may still be in the original buffer
Another func call can check if the buffer is free to use again (if the communication is finished by wait() or test().
Can be good for Isend() and do works and wait() —> improved performance.
The receive returns immediately; another call is to check for arrival.
Message Selection
The sending process calls
- a programmer defined msg tag can be used to create classes of msgs.
The receiver process calls
- buffer must be long enough for incoming message
Both have blocking semantics (send is either local or global)
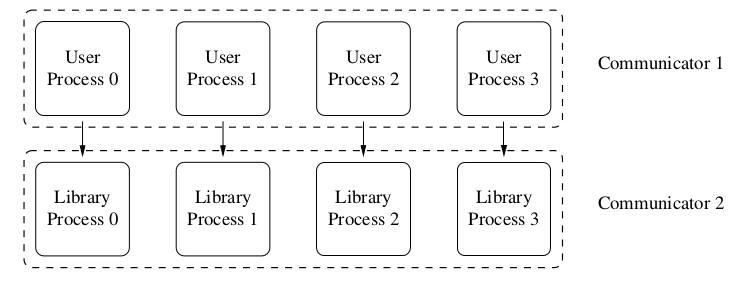
Comunicator
Definition: a group that processes can join.
It prevents conflict between msgs that are internal to a lib and those used by application program
Collective Operations
From simple send() and receive()
- Synchronization: barrier to inhibit further execution.
- Use simple pingpong between two processes.
- Broadcast: send same msg to many
- Must define processors in the group (that specified by communicator)
- Mush define who sends and receive
- May or may not sync processors (depends on the implementation)
- Scatter: 1 process sends unique data to every other in group
- Gather: 1 process receives …
- Reduction: Gather and combine with an operation (either to one or all)

