

Sliding Windows
- For reliability and throughput
만약 단방향 딜레이가 50ms 라고 한다면, Round-trip-time (RTT) 는 100ms
따라서 single segment (윈도우에서의 한 segment를 말한다) per RTT 라고 한다면
⇒ 10 packets/s (한 패킷 RTT = 100ms) - 10개의 segment 가 1초에 진행됨
이 상황에서는 대역폭이 증가해도 늘어나지가 않음, 왜냐면 이건 딜레이랑 관계된거니까
1 s = 1000 ms
Per connection 당 W 개의 segments-window 를 만든다고 가정해보자
다음과 같은 공식을 따른다 W = 2 * bandwdith * delay
예를들어 100 Mb/s, delay = 50ms 라면
- W = 2 * 100 Mb/s * 50ms = 200 Mb/s * 0.05 S = 10 Mb (윈도우 사이즈가 10메가 피트인거)
- 따라서 만약 한 segments 가 10kb 라면, W has 1000 segments
- 윈도우는 양방향 이므로 한 방향으로 500개의 segments가 있는것.
즉 윈도우는 양방향을 의미하며, 10Mb 사이즈의 윈도우라면, 각 방향으로 5Mb 씩 사용이 가능한것.
5Mb 양이 가는중이거나 오는중인것.
윈도우 Ack 하는 방식에는 여러가지가 존재한다
Go back N
Receiver: 단 한가지만 버퍼 한다 (1,2 이후에 3만 기다리는거)
- 만약 도착한 sequence 가 내가 기다린거면 오케이
- 만약 아니라면 뭐든 상관없이 싹다 버리고 내가 원하는거 올때까지 기다린다
- 시간제한이 지나면 해당 세그먼트를 재전송 하라고 송신자에게 요구한다
Sender
- 만약 일정시간내에 ACK를 받지 못하면 알아서 다시 보낸다
문제는 이 방식이 1 부터 100까지 보냈는데 수신자가 10 못받았다고 기다리면 10 부터 다시 보내야함
당연히 효율적이지 못함
Selective Repeat
Receiver: 여러가지를 버퍼한다 (예를들어 1,2, [], 4, [])
- 받은 순서대로 ACK 한다 (즉 내가 원하던게 순서대로이지 않아도 일단 ACK 보냄)
- 받지 못한것도 ACK (못 받았다고 알려주는거)
- 이 행위를 SACK (selective ACK) 라고 한다
Sender: 각 segment 별로 타이머가 따로 존재한다
- 시간내에 ACK 못받으면 알아서 보냄 (각 segment별로 타이머가 존재하는것을 상기하자)
훨씬 효율적이며 요즈음은 대중화됨
매우 송신자/네트워크 위주이다
- 송신자가 transmssion 을 담당한다
- UDP - 보내고 잊는다 (컨트롤 없음)
- TCP - 천천히 ACK를 기다린다 (메세지 전달을 보장함)
- 네트워크를 full로 쓸수 있게 optimize 한다
수신자가 송신자의 속도를 따라가지 못할 경우를 대비해서 flow control 이 필요하다
Flow Control: Receiver 쪽의 sliding windows
- Transport Layer:
- 네트워크로 부터 segment 를 받고, 어플리케이션 버퍼에 넣는다
- Application 은 recv(N-bytes) 를 이용해 버퍼로부터 읽는다
SYN 과 ACK 를 통해서 송수신자는 서로 어디까지 읽었는지 보내지만, 수신자가 flow control window (WIN)의 크기또한 송신자에게 같이 보낼수 있음
즉 WIN의 크기를 송신자에게 보내서 송신자는 지금 수신자가 어느 상태인지 알수 있는거.
- 더많이 읽을수 있는데 보내는 속도가 느린지, 아니면 거의 꽉차서 조금 위험해서 속도를 줄여야 하는지.
Congestion
- 교통체증: 뭔가 막혀서 지금 나머지 다 기다리는중
- 여러가지 이유로 존재 가능하며
- 어디서 무슨 이유로 이러는지 알 수 없음
- 송신자는 계속 보낸다
- 이는 상태를 개인이던 모두에게던 악화시킨다
- 혼잡은 곧 손실을 의미한다
Router Buffers: Queues
- FIFO on every interface
- 빠른 속도로 트래픽을 감당할 수 있다
- 문제는 이 큐가 오버플로우가 발생하면 패킷이 드롭되는것
- 보통 트래픽 패턴에 따라 좌지우지 된다
이렇게 패킷이 드랍되면, 수신자는 다시 보내라고 할거고, 송신자는 다시 보내고 결국 악순환이 이어짐
따라서 이러한 상황을 피하기 위해서 이 사태가 일어나기 직전까지 아슬아슬하게 성능을 최대한 유지하는게 관건 (물론 네트워크 상황은 변화기에 상황에 따라 알아서 변하는 알고리즘이어야 한다)
요점은 효율성 (최대한 네트워크 최대치를 사용) 그리고 공평하게 (모두가 비슷한 사용량)
Network layer 가 혼잡을 see 할수 있다 (IP - ICMP 말하는듯) 따라서 피드백을 줌
Transport layer 에서 혼잡이 일어난다 (큐 오버플로우 등) 따라서 송신자의 행동을 수정함
- TCP 윈도우 사이즈를 다이나믹 하게 조정한다
Statistical multiplexing 하면 안됨?
- 매우 어렵다
- 모든 어플리케이션은 다른 양상을 띄고 있고
- 로드는 항상 변하며
- 다양한 장소에서 혼잡이 발생 할 수 있고
- 한곳에서 전체적인 상황을 볼 수가 없다
- 따라서 이를 해결하기 위해서는
- 송신자가 지속적으로, 병행적으로 적응할수 있어야 한다
효율성과 공평성에서 가장 중요한것은 그 누구도 starvation을 겪으면 안되는것
그럼 송신자는 어떻게 “ADAPT” 할 수 있는가
- OPEN/CLOSE loop
- Open: 서킷을 미리 예약해 두는것
- Close: 피드백에 따라 적응하는거
- Host or Network driven
- Host: 얼마나 사용할지 호스트가 정하는거
- Network: 네트워크가 규약으로 정해둔거 (유동적이지 못함)
- Allocate bandwidth via
- Rate Based : 어플리케이션에게 어느 속도로 보낼지 알려줌
- Widows size : 윈도우 사이즈 (control flow)로 보고 정함
TCP의 경우 Closed, host, window based 이다.
Additive Increase, Multiplicative Decrease (AIMD)
- 송신자는 천천히 송신율을 올린다
- 혼잡을 일으키는 숫자를 줄이니,결국 더 많이 보내는것
- 혼잡이 발생하는 순간 배수적으로 송신율을 줄인다
- 빨리 줄여서 혼잡을 최소화 시키는것
- 장점:
- 모든 호스트가 이 방법을 쓰면 모두 공평하고 효율적으로 대역폭을 사용할 수 있음
- 위상을 알 필요가 없음 (왜냐면 피드백 위주니까)
- 모두가 (조금씩 다른 방법으로 ) 한다
- 다른 control law 에 비해 효과적으로 작동함
- 네트워크로부터 단 한가지의 신호만을 필요로함 (사실 리시버로부터)
- 왜냐면 수신자가 혼잡 상황에 대해 알려주기만 하면됨 밑의 표를 참조
- 모든 호스트가 이 방법을 쓰면 모두 공평하고 효율적으로 대역폭을 사용할 수 있음
AIMD implementation
ACK Clocking
- ACK가 돌아오는 속도를 보고 송신자가 이에 맞추는것
- 보낸 속도보다 ACK 돌아오는 속도가 적다면, 중간에 무슨 이유던간 라우터가 buffer 에 저장되어 있는 상태를 의미하기에, 이 라우터 버퍼 오버플로우를 방지하기 위해 속도를 줄이는거
- 이 돌아오는 속도로 Congestion Window (CWND) 를 계산 할 수 있다
- W (window size) 보다 작다, 또한 CWND 는 WIN 과 전혀 관계없다
- WIN 은 수신자 컨트롤 플로우 사이즈이고, 혼잡 CWND는 라우터에 관한거 (혹은 네트워크 전반)
- W (window size) 보다 작다, 또한 CWND 는 WIN 과 전혀 관계없다
- 적은 손실과 딜레이를 네트워크상에 가능하게 한다.
- Clocking 을 통해, burst 를 smooth 하게 바꾸면서도 같은 송신율을 유지한다
- 중간 라우터에서 queue up 하지 않으니까
- Clocking 을 통해, burst 를 smooth 하게 바꾸면서도 같은 송신율을 유지한다
그렇다면 이 CWND를 처음에 어떻게 알 수 있을까?
처음 1 패킷 부터 보내기 시작해서, 손실 없이 ACK가 돌아오면 CWND 를 1씩 더한다
⇒ 이 방식은 매우 안전하지만 동시에 매우 느리다 (이는 곧 비효율성을 의미한다)
따라서 이 CWND의 효율적인 증가및 감소를 위한 알고리즘이 바로
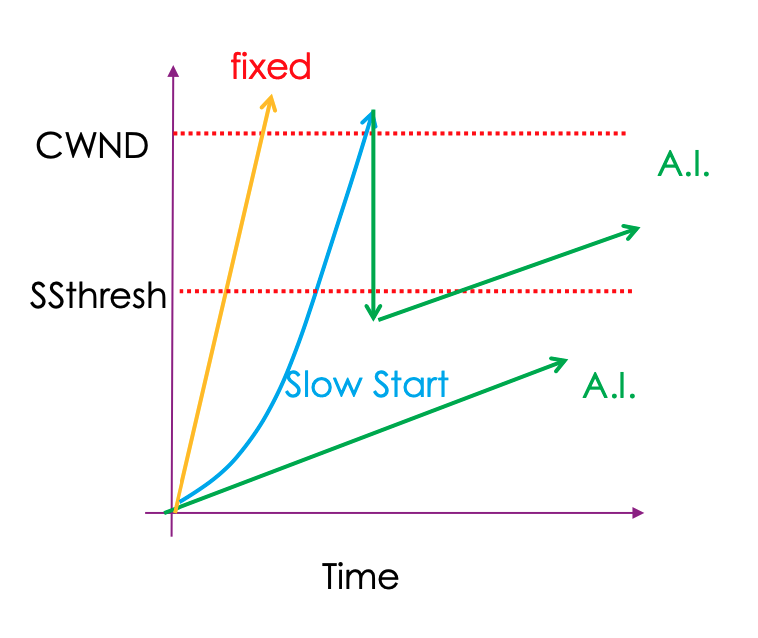
TCP Slow Start
- 극 초기에 (1부터 시작할때) 1씩 더하지 말고 ACK 가 올떄마다 2씩 증가시키는거
- 첫 시작은 slow (1이니까) 대신 빠르게 속도를 올림
- 배수로 증가시키기에 어느 한순간 급작스럽게 congestion을 만들어 패킷 손실/피드백을 받을것이다
- 이럴 경우 multiplicative 하게 감소한다. 이 감소 방법에는 여러가지 버전이 있지만 초기버전의 경우
- Threshold: ss-thresh = 0.5 * CWND (@ loss) (Reno 방식이다)
- 이 순간부터는 배수가 아닌 더하기 형식으로 증가한다.
Fast retransmit (빠른 재전송)
- Pre-SACK: 만약 기다리던 segment 가 아닌 다른 세그먼트가 도착한다면
- 예를들어 92 108 116 124 가 도착했다고 하자
- ACK는 기다리는 넘버를 의미하니 수신자가 송신자에게 ACK 100 을 보내야 한다
- 108 이 도착하면 ACK 100, 116 이 도착하면 ACK 100, 124 가 도착해도 ACK 100 을 보낸다
- 이 ACK 100 이 세번 도착하면 해당 100 데이터를 (타이머가 되기전에) 빠르게 다시 보낸다
- 만약 잘 도착했다면, 현재 내가 보낸 데이터들 다음 번호인 132 (124+8) 이 도착할것이고
- 만약 100 이후에 잃어버린 세그먼트가 있다면 그 세그먼트에 대해서 ACK를 보낼것이다
따라서 타임아웃 되기전에 빠르게 고치려고 하는것.
주의 해야 하는점은 빠른 재전송의 경우 같은 ACK를 세번 받았을때 행해진다. 이 빠른 재전송이 일어나면 CWND 를 반으로 줄여야 한다. 타임아웃이 일어나면 1부터 다시 시작하는것
초기 모델은 이 타임아웃과 ACK 3번 중복을 받으면 (둘중 하나) 그럼 바로 1부터 시작했음
현 Reno의 경우 타임아웃은 심각하게 (1부터) 3-중복은 덜 심각하게 (* 0.5) 받아 들인다.
Fast Recovery (빠른 회복)
빠른 재전송이 일어났으면 일단 cwnd 는 반으로 줄이고,
- 빠른 재전송이후 seq number 가 어디에 있는지 기다린다 (즉 이 기간동안 기다린다 패킷 보내지 않고)
- 기다리는 동안 해당 100 ACK 이 오면 cwnd 1씩 증가
- 만약 그 다음 segment 들이 모두 성공적으로 도착했다면 (catch up 헀다면), 반으로 감소시킨 CWND 로부터 증가시켜 간다 (ACK Clock 을 유지한다)
- 안고쳐지면 타임아웃이 일어날거임, 그럼 cwnd = 1, ACK clock 또한 초기화 한다.
여러가지 방식들이 존재한다
TCP Reno
- 위의 얘기한 0.5를 곱하는 방식이다. 이 방식은 한 손실을 고칠수 있다 per RTT
- 즉 하나 손실하면, 보내고 기다리고 (고쳐진지 확인)
- 만약 여러 손실이 발생하면 CWND 를 반으로 감소시킨다
TCP New Reno
- ACK 분석이 더 좋으며, 이로 인해 여러 손실들을 고칠수 있다 per RTT
TCP SACK
- 훨씬 좋다, 수신자가 ACK를 범위 단계로 보내기 때문에 송신자가 필요한것만 여러개 딱딱 보낼수 있음.

