

Reference :
- Introduction to Parallel Computing, Edition Second by Vipin Kumar et al
- The Australian National University CECS
Shared Memory Hardware
Uniform Memory Acccess Shared Address Space with cache: 보통 UMA와 같지만 로컬 캐시를 가지고 있음
NUMA with cache: 보통 NUMA와 비슷함. 프로세서, 캐시, 메모리 한그룹이 묶여있고 이 그룹이 Interconnection Network을 통해서 연결되어 있음.
Shared Address Space Systems
- 만약 로컬 메모리에 대한 접근이 원격 접근보다 가격이 싸다면 (즉 NUMA) 보다 싸다면 Shared Address Space Systems가 알고리즘에 포함되어야 함.
- 어떻게, 운영체제가 호환되는지는 다른 문제임
- 보통 공유 주소 공간을 가지고 있는게 프로그래밍 하기 쉬운이유가, 읽기 전용의 시스템은 그냥 순차적 프로그램 짜듯이 짜면됨. 다란 읽기/쓰기 같은경우, 병행적 접근때문에 MUTEX 가 필요함.
- 주요 프로그래밍 모델들은 쓰레드와 directive based (컴파일러에 해당 인풋을 어떻게 처리할지 지시하는 언어적 구조) 이다. (Pthreads and OpenMP)
- 동기화는 락과 관련된 메카니즘을 사용한다.
SASS with Shared memory computers
- 공유 메모리는 전통적으로 메모리가 물질적으로 여러 프로세서들에게 연결되고, 모든 프로세서가 해당 메모리에 동일한 접근 권한을 가진곳에 사용되어 왔다.
- 해당 방식은 UMA 라고 한다.
- SMP는 원래 Symmetric Multi-Processor라 하여 모든 CPU들이 동일한 운영체제 성능을 (인터럽트나 다른 시스템콜 등) 가진것을 칭했는데, 요즘은 Shared Memory Processor의 축약어이다.
- 분산 메모리 컴퓨터는 각 메모리의 다른 부분이 물질적으로 다른 프로세서와 연결되어 있음에 차이점이 존재한다. 이 distributed momory shared address space computer를 NUMA 시스템이라 한다.
멀티프로세서에서의 캐시
여러장의 데이터들이 여러 프로세서들에 의해 값이 변화된다.
- 시스템 안의 각각의 물리적인 메모리 워드를 찾아낼 수 있는 주소변환 메카니즘, 그리고 여러 데이터들의 병행적 수행들이 잘 정의된 세만틱들을 가지고 있어야 한다.
- 여러 프로세서들의 접근에 의한 캐시값의 일관성유지가 필요함.
- 몇 기기들은 공유 주소 공간 메커니즘까지만 관여하고 일관성은 시스템이나 유저레벨의 소프트웨어에 일임한다.
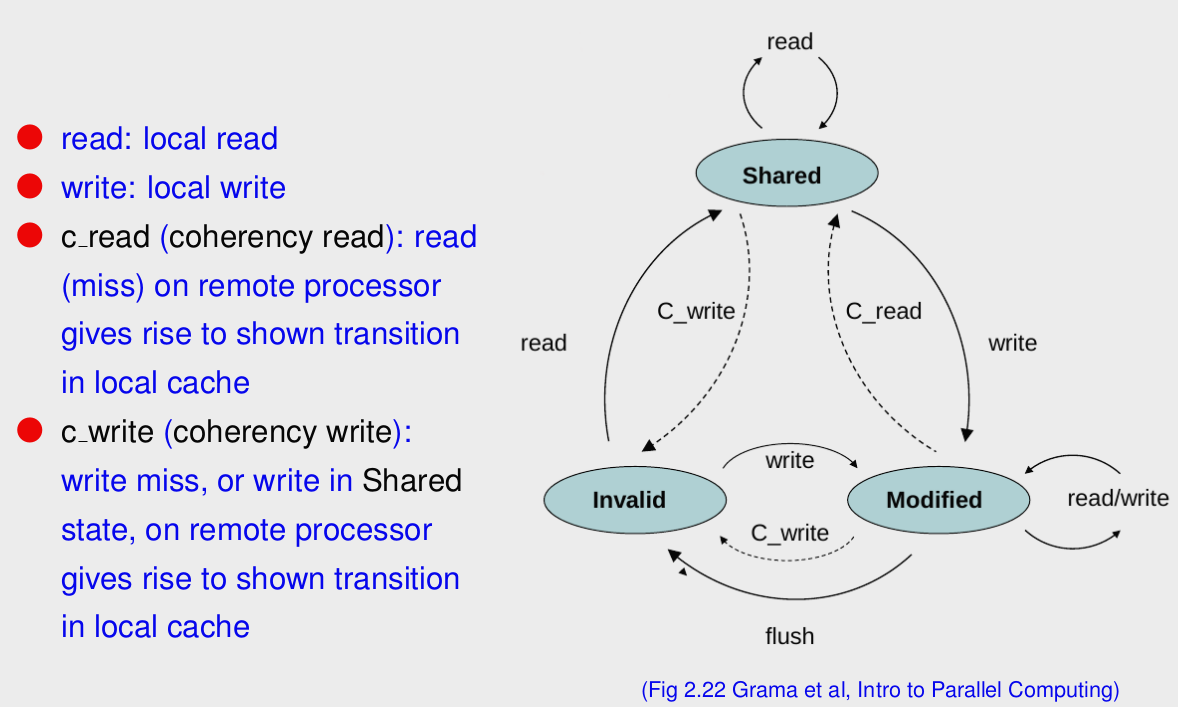
Cache/memory Coherency
- 매모리 시스템은 다음 사항들을 지키면 일관적이다
- 실행된 순서대로 (Ordered as Issued) : 즉 한 프로세서가 읽고 수정하는동안, 다른 프로세서가 해당 값은 수정하지 않을때 (읽기는 가능)
- 쓰기 전달 (Write Propagation): p1 reads, p2 writes, then p1 should have value of p2.
- Write Serialization: 다른 프로세서들이 볼때 두 프로세서가 두 쓰기를 실행한 순서를 정확히 알고 있다면.
Cache Coherency Proctocol
Invalidate Protocol: P0 P1이 같은 값을 읽었는데 P0가 값을 바꾸면, 해당 메모리와 이 값을 읽은 P1에게 이 값은 Invalidate되었음을 알려주는 방식 (이 값 쓰지마라) - 보통 이 방식을 사용
Update Protocol: P0 P1이 같은 값을 읽었는데 P0가 값을 바꾸면, 메모리와 P1이 가지고 있는 해당값을 업데이트 해줌.
비교:
- 업데이트 프로토콜의 경우 같은 단어에 대한 여러 쓰기는 (거의 동시 읽기) 여러 쓰기 브로드캐스트s 를 필요로 한다. 이에 비해 Invalidate는 단 하나의 initial invalidation을 필요로 함.
- 업데이트 프로토콜의 경우 여러 복수단어들의 캐시 블록들에게 각각의 캐시 블록 (라인)에 쓰여진 각각의 값들은 브로드캐스트 되어야 한다. 즉 한 블록에 한 단어만 보낼수 있음 (즉 여러 n 값들은 n번 보내져야 함). 반대로 invalidate only require one line.
- 업데이트 프로토콜의 경우 한 프로세서가 한 값을 쓰고, 이 쓰여진 값이 다른곳에서 읽혀지는데 걸리는 지연시간이 더 적다. (즉 invalidate에 비해 값이 쓰여지고 읽혀지는 지연이 짧다는말)
False Sharing
두 프로세서는 같은 캐쉬라인에서 다른 부분을 수정함.
Invalidate의 경우 핑퐁된 캐시 라인들을 이용한다.
Update의 경우 로컬로 읽지만, 프로세서간의 업데이트 트래픽을 많이 발생시킨다.
다음 사항들을 병력 프로그래밍이나 시스템을 디자인 할때 항상 염두해야한다
- 캐시라인 사이즈, 길수록 좋다
- 캐시 라인 사이즈를 고려한 데이터 구조의 alignment
Implementation of Cache Coherency
- 조그만 스케일의 버스 기반 기기들의 경우
- 한 프로세서는 반드시 쓰기 invalidation을 브로드캐스트 할 수 있도록 버스에 대한 접근 할 수 있어야 한다.
- 경쟁하는 두 프로세서들의 경우, 먼저 버스에 접근을 얻는 프로세서가 해당 데이터를 invalidate 한다 (즉 먼저 오는 프로세서의 값을 사용하는것)
- 캐시 미스의 경우 데이터의 최신 카피를 위치해야 한다.
- write-through cache 의 경우 쉬움
- Write-back cache의 경우, 각 프로세서들의 캐시는 버스를 감시하며 데이터의 최신 카피가 있다면 반응한다 (snoop - 감시)
- 읽기의 경우 다른 카피들이 해당 블록을 캐시했는지 알고싶어한다 (즉 해당 블록이 사용중인지)
- write-back cache가 버스에 detail을 넣을지 말지 결정하기 위해서라던지
- 태그를 이용해서 공유 status를 통해 관리한다
- 프로세서 멈춤을 최소화하기
- 태그들의 복사나, 혹은 inclusive cache 를 여러개 갖던지 하는 방식으로
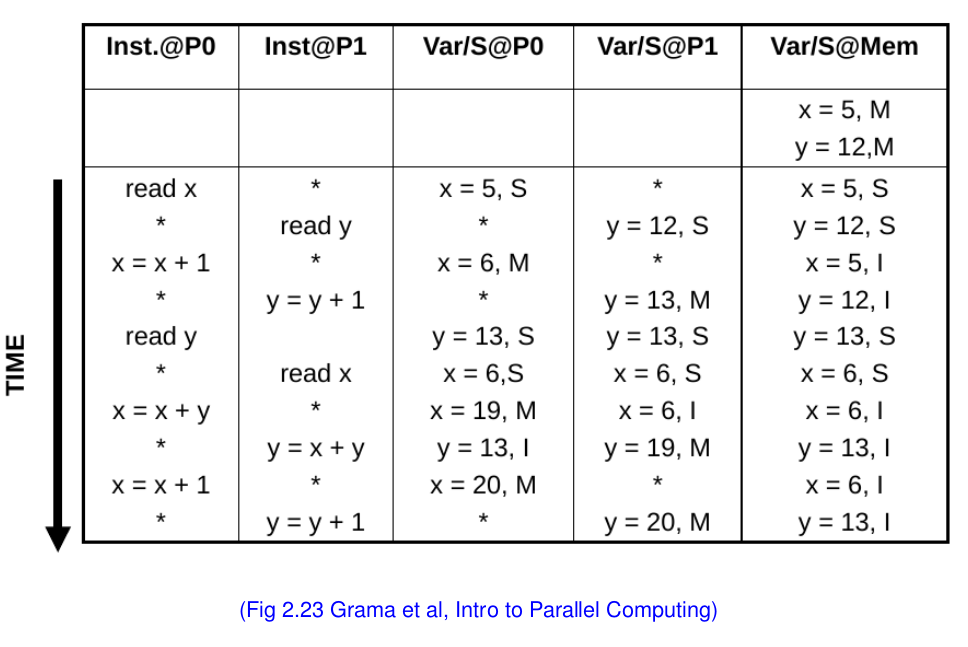
위 그래프와 아래 값들의 변화를 주의해서 살펴본다.
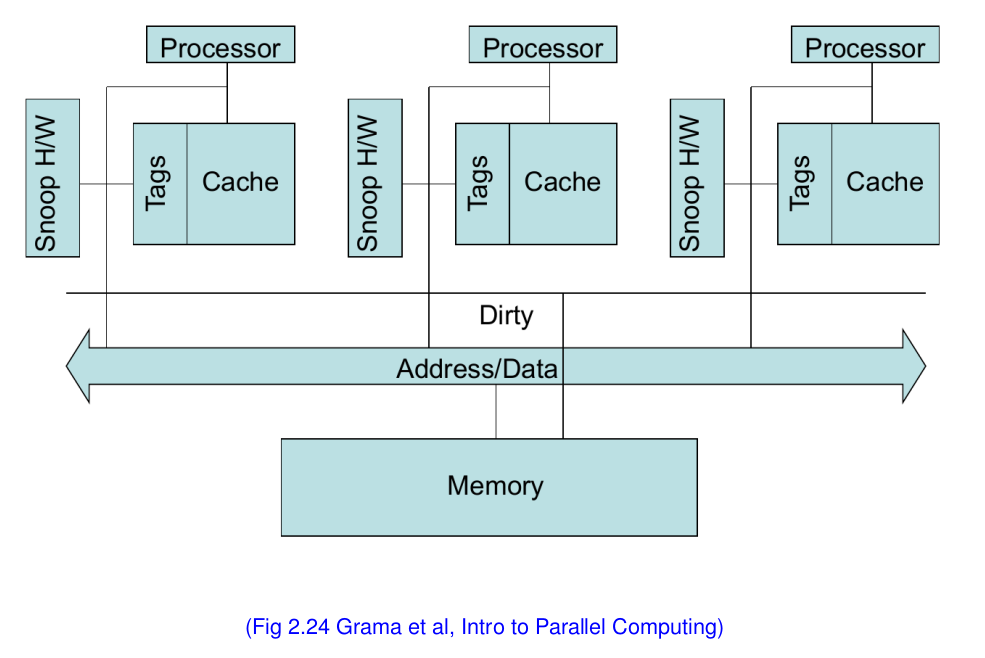
스누피 캐시 시스템
- 모든 캐시들은 모든 변화를 브로드캐스트 한다
- 버스나 링 위상의 interconnects에 쉽게 적합할수 있다 (implement)
- 그러나 확장성이 재한되어 있다 (8개 이하).
- 모든 프로세서들의 캐시들은 interconnect port의 변화를 감지한다 (관심있는 부분만)
- 관련 프로토콜의 상태 다이어그램을 통해 태그들이 업데이트 된다.
- 하드웨어 감시는 읽기가 한 더러운 카피를 가지고 있는 캐시블록에 대해 읽기가 실행되었으며, 이 행위가 버스 컨트롤에서 데이터를 빼내고, 관련 태그를 S로 바꾸었음을 알아차릴 수 있다. (예를 들어)
Directory Cache-Based Systems
디렉터리 기반 일관성 구조는 캐시 블록의 공유 상태, 노드 등을 기록하는 저장 공간인 디렉터리를 이용하여 관리하는 구조이다 - presence bitmap을 전역 메모리와 함깨 이용하여 각각의 메모리 블락이 어느 캐시에 위치하고 있는지를 디렉터리에 저장하는 방식.
이에 반해 디렉터리 기반 구조는 어떤 노드에서 해당 캐시 블록의 복사본을 가지고 있는지를 알고 있기 때문에 특정 노드에만 요청을 하게 된다. 따라서 브로드캐스트가 불필요하게 되어 대역폭이 상대적으로 작아도 된다. 이 때문에 64개 이상의 프로세서를 가지는 대규모 시스템에서는 디렉터리 기반의 캐시 일관성 프로토콜을 사용하는 경우가 많다.
이 디렉터리는 메모리와 붙어 있는데 공유 메모리의 경우 디렉터리가 따로, 로컬 메모리를 이용하는 경우 각각의 로컬 디렉터리를 사용한다.
- 쉬운 프로토콜은 다음과 같을것이다
- shared: 프로세서들은 블락 캐시를 가지고 있고, 메모리 값은 최신화를 유지한다
- Uncached: 어느 프로세서도 카피를 가지고 있지 않는다 (즉 뺴서 저장하고 하지 않음)
- Exclusive: 오직 한 프로세서만 (주인) 카피를 가지고 있고, 메모리에 있는 값은 옛날 값이다.
- 공유되고 깨끗한 캐시 블록에대해 쓰기/읽기 미스와 쓰기는 다음과 같은 사항을 반드시 지켜야 한다
- 이 블록에 대한 현 상태를 체크하기 위해 디렉터리 주소를 처음에 참조해야한다 (즉 directory entry를 먼저 refernce해서 상태 체크 해야함)
- 그후에 entry의 상태와 presence bitmap을 업데이트한다
- presence bitmap에 있는 해당 프로세서들에게 적절한 상태 업데이트 소식을 전달한다.
디렉터리 기반 시스템의 문제점
디렉터리 저장의 메모리 요구량
특정 데이터 접근 방법에 따른 퍼포먼스 차이
presence bitmap을 어떻게 관리할것인지 (복사? 꼭?)
어떻게 presence bitmap에 존재하는 모든 프로세서들에게 invalidation을 보낼것인지
- MESI 프로토콜 출처
- 캐시 메모리의 일관성을 유지하기 위해서 별도의 플래그(flag)를 할당한 후 플래그의 상태를 통해 데이터의 유효성 여부를 판단하는 프로토콜이다.
- 데이터 캐시는 태그 당 두 개의 상태 비트를 포함한다.
- 멀티프로세서 시스템에서 캐시 메모리의 일관성을 유지하기 위해 메모리가 가질 수 있는 4가지 상태를 정의한다.
- Modified(수정) 상태 : 데이터가 수정된 상태
- Exclusive(배타) 상태 : 유일한 복사복이며, 주기억장치의 내용과 동일한 상태
- Shared(공유) 상태 : 데이터가 두 개 이상의 프로세서 캐쉬에 적재되어 있는 상태
- Invalid(무효) 상태 : 데이터가 다른 프로세스에 의해 수정되어 무효화된 상태
Coherency Wall - 캐시 일관성의 한계및 단점
- 인터커넥트는 로직 서킷들에 비해 50배나 넘는 에너지를 소모함
- 각각의 invalidation을 위해 브로드캐스트 메세지를 필요로 하는 프로토콜의 경우
- 에너지 소비는 O(p), overall cost = O(P^2)
- 네트워크의 지연을 일으키기도 하다
- 디렉터리 기반 프로토콜은 같은 데이터를 들고 있는 곳에만 메세지를 보낸다
- 훨씬 확장성이 높으며 가벼운 데이터 공유를 가진다 (가진 애들끼리만 대화 하니까)
- 이외는 모두 안좋다 잘못된 direction으로 인한 오버헤드도 발생함
- 한 캐시 라인당, 비트 벡터의 길이가 a 라 하면 O(a^2) 의 공간 소모
- false sharing은 어느 경우라고 트래픽을 낭비하는 모습을 보여줌
- Atomic instructions 메모리 시스템의 동기화를 LLC (Last level cache) 까지 낮추는데 비용이 각각 O(p)
정리
- 캐시 일관성은 실행 순서, 쓰기 전달, 쓰기 순차 세개의 요소를 가지고 있다
- 두가지 방식을 가지고 있는데
- 브로드캐스트/스눕: 중소 규모의 인트라 칩, 그리고 작은 인터 소켓시스템에 적합
- 디렉터리 기반: 대중 규모의 인터 소켓 시스템에 적합
- False sharing: 잠재적인 퍼포먼스 문제가 있음 (특히 캐시 라인이 길어질수록)
- 대규모의 인트라 칩 시스템의 경우 일관성은 보통 운영체제나, Message Passing 프로그래밍 모델을 이용한다.

