Reference : Introduction to Parallel Computing, Edition Second by Vipin Kumar et al
Why parallel is hard?
- Writing (correct & efficient) : hard to debug
- Getting (ideal) speed up:
- communication shared data
- Synchronization (barriers and locks)
- need for redundant computations (balancing load evenly)
- Parallel approach is not always right.
Design of diff processor type:
Single Processor Design
- Same Language
- many happens within a single processor
- Potential issues for hardware side
Multiple Processor Design
- Architectural Classifications
- Shared/Distributed memory
- hierarchical/flat memory
- dynamic/static processor connectivity
- Evaluating static networks
Adding two double precision (8) = 8*8 = 64 bits
- Determine largest exponent (가장 큰 제곱수 - 지수)
- Normalize significand (밑수) of small exponent to the larger - 지수 밑수로 식 바꾸는거
- Add significand (같은 지수의 밑수들 끼리 더해주기)
- 재정립 (올림내림 등등)
— Each taking 1 tick → Total 4 ticks per addition (FLOP)
Instruction Pipelining (https://namu.wiki/w/파이프라인(CPU))
break an instruction into k stages ⇒ ≤ k-way || ism (instruction mix)
FI = Fetch Instrn (불러오기) DI = Decode Instrn (해석하기) FO = Fetch Operand (함수 불러오기) EX = Execute Instrn (실행하기) WB = Write Back (값 적기)
- Conditional Branch - wrong guess may result flushing succeeding instructions from the pipeline.
- More breakdown stages → Increase in startup latency.
Pipelining: Dependent Instrn.
Principle = CPU must ensure result is the same as if no pipelining (or ||ism)
위 상기한 것중 EX의 실행하기 단계가 여러개의 사이클을 필요로 한다면 (3 사이클), EX1, EX2 처럼 연속적으로 늘어난다 (같은 카테고리에 속해있기에 dependent 하다).
SuperScala (https://namu.wiki/w/슈퍼스칼라)
- 파이프라인 기업을 통한 CPU 속도 향상위한 컴퓨터 구조 설계 방식
SMT (Simultaneous multi-threading) 는 쓰레드 레벨에서의 병렬화, 슈퍼스칼라는 명령어 레벨에서의 병렬화다.
명령어 레벨 병렬화는 명령어간의 종속성을 최소화 해야하는데, 이로 인해 복잡한 명령어 스케쥴링이 필요하다. 이용해서 하나의 코어 파이프라인에 여러 쓰레드에 포함된 명령어를 섞어서 집어넣으면 스케줄링의 복잡성을 억제하면서도 효율적인 파이프라인 활용이 가능해진다.
problem: amplifies dependencies and other problems of pipelining by a factor of w!
구현방식
In Order Execution : 해저드 방지를 위해 순서를 기다려야 해서 처리 속도에서 손해
Out of order Execution : Implement Reorder Buffer - 버퍼 안에 배열을 해 두고 순차 관계 없이 바로 처리하는것. If branch prediction failure, need to empty the buffer and fetch the instrn fast. The bottle neck happens. 이때 명령어를 한번에 읽어오는 구조를 슈퍼스칼라 라고 한다.
Memory
Typically a processor can only issue one load or store instrn
Memory latency and bandwidth are critical performance issues
Main memory : large cheap memory with large latency and small bandwidth
Cache: Opposite of main memory
To reduce the time of fetching, try to ensure data is in cache (or as close to the CPU as possible)
Cache memory is effective because algorithms often use data that:
● was recently accessed from memory (temporal locality) - 최근에 사용된 메모리
● was close to other recently accessed data (spatial locality) - 최근에 사용된 메모리에서 가까운것
메인 메모리의 경우 블락들이 각각의 캐쉬에 맵핑이 되어있음 (직접적이든 간접적으로든).
캐쉬는 보통 16-128 바이트 사이
Entire cache line is fetched from memory, not just one element (why?)
■ try to structure code to use an entire cache line of data (한번에 복사되니까 모두 쓰게끔)
■ best to have unit stride (어레이 처럼 사이에 공간 없이 연속적인 유닛)
■ pointer chasing is very bad! (large address ‘strides’ guaranteed!) (이리저리 메모리 주소를 돌아다녀서)
Memory bandwidth (전자기적 영역) can be improved by having multiple parallel paths to/from memory, organized in b banks - Unit Stirde 일때 효율적이며, 벡터 프로세싱에 좋고, bank-conflicts 일어나면 한가지 뱅크만 사용될 수도 있다.
당연하게도
- 필연적으로 프로세서는 클럭 속도에 따라 퍼포먼스가 제한된다
- 아무리 클럭 속도를 올리더라도 물리학상 빛의 속도 이하로 제한된다
- ILP는 여러 명령을 한번에 실행가능 하지만 제한이 있다.
하드웨어 문제:
Architecture Classification (Flynn’s Taxonomy)
- SISD: 1 CPU
- MISD: Pipelined?
- SIMD: Array/Vector Processor
- Data Parallel / Array Processor and Vector (in some extent)
- CPUs are controlled by one global control unit
- MIMD: Multiple Processor
- Most Successful parallel
- Each CPU is dealt by each control unit.
- Hence, processors are not synchronised → harder to program
- 스케쥴링 - 프로세서들에게 효율적인 일 분배
- 싱크 - 같은 데이터 동시 접근 방지
- 연결 디자인 - 프로세서/메모리 혹 프로세서/프로세서 연결
- 미리보기 - 자원 문제등 방지 위한 어느정도의 overhead
- 파티셔닝 - 동시 처리 스트림을 이용할 수있는 알고리즘에서 병렬 처리를 식별하는 것은 쉽지 않습니다.
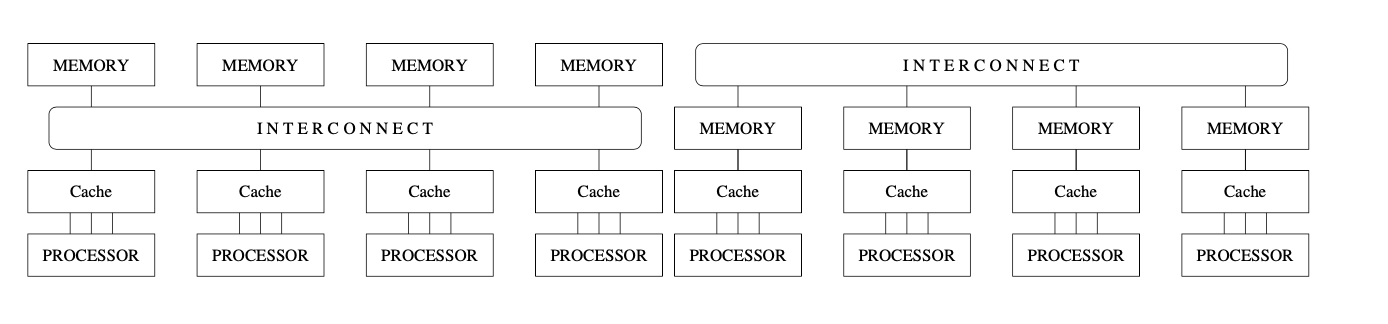
Address Space Organization
Message Passing (Distributed Parallel Computers)
- Each processor has local/private memory (메모리 공유가 아니기에)
- Interact solely by MP. (메세지 패싱으로만 서로)
- 프로세서 수에 따라 대역폭이 결정됨
Shared Address Space
- Interact by modifying data objects in a shared address space (공유 메모리)
- All the processors in the UMA model share the physical memory uniformly. In an UMA architecture, access time to a memory location is independent of which processor makes the request or which memory chip contains the transferred data (모두 공유하기 때문에 메모리 엑세스 시간이 프로세서나 메모리 위치에 따라 변하거나 하지는 않는다)
- 메모리 대역폭이나 프로세서간 커뮤니케이션의 확장성에 문제가 있다.
Non-Uniform Memory Access (NUMA)
- 메모리간의 서열이 존재한다
- 모든 메모리에 접근 가능하지만, 위치에 따라 엑세스 시간이 달라진다 (머니까)
- 이에 따라서 중간에 캐쉬를 넣어 놓음 (fetching speed 빠르니까)
Shared Address Space Access
Parallel Random Access Machine (PRAM) : any shared memory machine
Exclusive-read, exclusive-write (EREW PRAM)
Concurrent-read, exclusive-write (CREW PRAM)
Exclusive-read, concurrent-write (ERCW PRAM)
Concurrent-read, concurrent-write (CRCW PRAM)
Concurrent Write 다음과 같이 관리한다:
- Common : 값이 같으면 가능
- Arbitrary : 아무 한 프로세서만 가능하고 나머지는 거절
- Priority : 프로세서간 우선순위 설정
- Sum : 모든 결과값 더하기 (즉 더하기 였으면 합쳐서 더해도 같으니까)
Dynamic Processor Connectivity
Switch is a mapping from the input to the output ports (# of switches = degree of switch)
switches: internal buffering (출력 포트가 사용중일때), routing (네트워크 혼잡을 완화하기 위해), multi-cast (여러 포트에 동일 출력) 을 지원할 수 있다. 밑의 메커니즘 = mapping between input & output.
매핑 하드웨어는 스위치 개수의 제곱, 주변 하드웨어와는 선형, 패키비지용은 핀의 개수와 선형으로 증가.
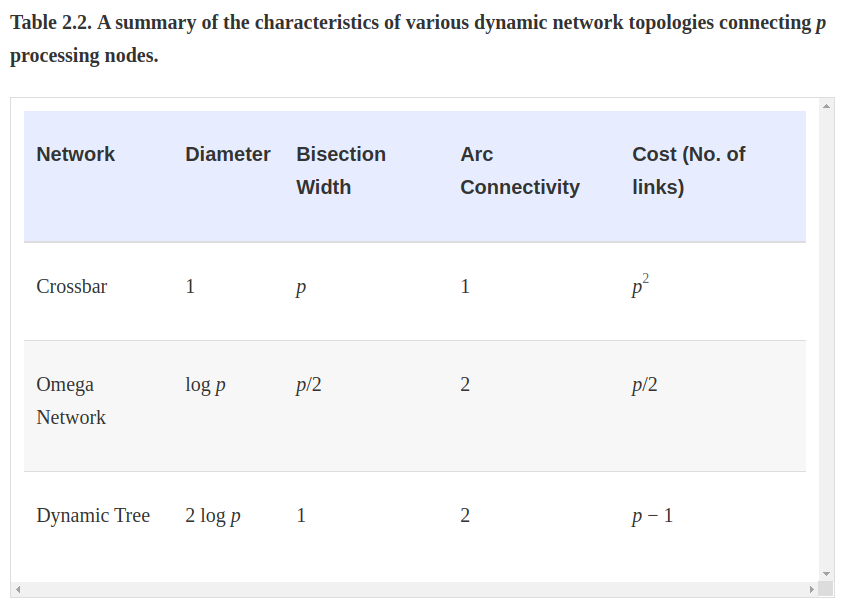
- Crossbar (프로세서가 많을 때 좋음) - 비용면에서 확장성이 뛰어나지 않음 (성능 확장 가능)
- non-blocking network : 프로세서의 통신이 다른 프로세서간을 방해하지 않음
- network comp = Omega(p^2) - 스위치 복잡성으로 인해 높은 데이터 속도 실현 어렵
- 각 프로세서간 연결에서 로컬 메모리와 함께 연결도 가능하다.
- 다양한 메모리 뱅크를 가진 프로세서간 연결도 가능하다.
- 비용 theta(p^2)
- Multi-staged Networks (네트워크를 통하니 프로세서가 적당할때) - 성능비용 1,3 사이에 위치
- O(lg p), 네트워크 비용은 theta(p lg p)
- 해당 메모리 뱅크를 사용할 때 다른 프로세서간의 연결 (그 메모리 뱅크 사용)을 차단함
- route if MSB of s and t are the same; if not crossover.
- 010 (s) - 100 (so out through 101) - 011 (so 011) - 110 (cross to 111) - 111
- 한 스위칭 네트워크를 지나면 비트를 쉬프트 한다 (010 에서 0,1,0 순서로 비교)
- BUS (프로세서가 적을때) - 브로드캐스트에 적합 (성능 확장 불가, 비용면에서 확장 가능)
- 메모리 접근을 위해 버스를 통하는데, 버스는 독점적인 접근만 허용한다 (한명만)
- 따라서 버스의 퍼포먼스는 확장성이 제한된다 - 보통 12개 정도 까지
- cost for expansion = p and the distance bet two nodes are O(1) - directly connected
Network Topology
- Completely Connected - crossbar (non block communication) + static (directily point to point)
- Star Conncted - One processor acts as a central processor (bottleneck) → bus-based network
- K-D Mesh -
- 병렬 컴퓨터 보통 3차원 문제 다룸 ⇒ 3D 큐브를 보통 사용함 (Linear array)
- Hypercube - 대응 노드에 따른 연결 (3차원은 2차원 두개, 4차원은 3차원 두개 식으로 증가)
- Hamming Distance : xor 로 인한 거리 구하기 (블록 코드의 일종) 하이퍼 큐브에서 해밍 거리는 두 프로세서간 가장 짧은 거리의 값이다.
- Tree Based - only one path between any pair of nodes. 선형/스타 형식은 트리 네트워크의 일종. 프로세서가 메세지를 하위 루트 (송수신 노드 모두 포함) 까지 위로 보내고 거기서 내려주는 형식
- 다이나믹 트리: 리프들이 프로세서, 그 위는 스위칭 노드
- 트리 네트워크는 상위 레벨에서 병목현상이 심함 - 통신 링크 증가, 노드를 루트에 다 가깝게 전환 해서 다이나믹 트리에서 완화 할 수 있다.
- 이진트리는 루트를 통해 오는만큼 병목 현상이 심하나, 이를 고안한 뚱뚱한 상호 접속 나무가 있다 (fat tree interconnect) 리프노드만 프로세서를 가지고 있고, 성능을 저하시키지 않으며 파티션이 가능한데 이는 슈퍼컴퓨터에게 굉장히 유용하다.
Static Interconnection Network
Diameter : 두 프로세서간 네트워크상 최단 경로상 가장 먼 거리
Connectivity : 두 프로세서간 가능한 루트 (많을 수록 강한 연결을 뜻하니 좋다 - minimize fault-tolerance)
이 연결성은 비연결 네트워크 두개를 만들기 위해 제거 해야하는 아크의 최소 숫자로 구분짓는다

Channel Width : 두 프로세서간의 링크에서 동시교환 가능한 비트의 수 (= 두 노드간 연결된 물리 링크 갯수와 같다)
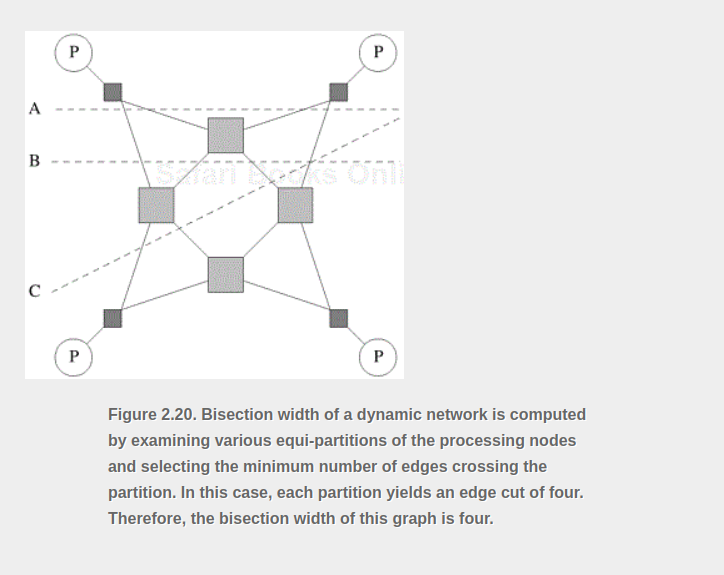
Bisection width : 네트워크를 정확히 이등분 하기 위해 지워야 하는 링크 숫자 (단절시키기 위해)
Bisection bandwidth :
- 같은 수의 프로세서를 가진 네트워크의 이등분을 위한 최소 커뮤니케이션 볼륨 (그래야 제일 비슷하게 나뉘어진거니까) - 이 값은 전체 시스템의 진실된 대역폭이며 병목 대역폭을 의미하기도 하기 때문에 중요하다.
- = bisection width * channel bandwidth (= channel rate * channel width) = cross-section bandwidth,
- can also be used as a measure of its cost. It provides a lower bound on the area.

Dynamic Interconnection Network
- Diameter : max disatance between two nodes (indicative of max latency)
- Connectivity:
- node connectivity : min num of nodes that must fail to fragment the network into two.
- cosidering all nodes gives a good approximation to the paths (=arc connectivity in a similar usage) - althogh we only should consider switch nodes.
- Bisection Width: consider any possible partitioning of the p processing nodes into two equal parts. - 파티션을 가로지르는 엣지 수가 최소인 파티셔닝을 선택한다 이 최소 엣지수가 이분 폭
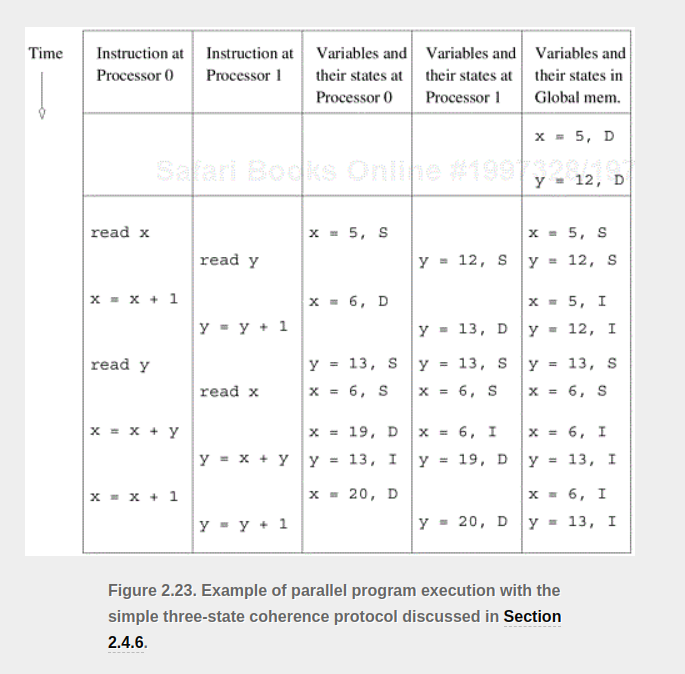
Cache Coherence : 캐쉬값을 일관성있게 유지하기
- 무효화 프로토콜 : p0의 값이 1에서 3으로 변경됬을때 p1값 (1)과 비교후 같지 않으면 모두 무효처리
- 캐시 라인 다른 부분을 업데이트 하면 알아차리지 못함 (false sharing)
- 이로 인해 일부를 업데이트 하면 다른 프로세서의 값이 무효화 됨
- 이 값을 제대로 가지기 위해선 해당 라인을 따로 원격 프로세서에서 가져와야 함
- 업데이트 프로토콜: 한 프로세서에서 캐쉬값이 바뀌면 p1값을 3으로 업데이트 후 메모리도 3으로 바꿈
- p0가 값을 읽고 사용을 안하면, p1 에서 소스 대기시간 + 네트워크 대역폭 오버헤드 이 발생함
- False-sharing 에서 업데이트 프로토컬은 모든 값을 업데이트 하므로 무효화 프로토콜 보다 낫다.
이 두 프로토콜은 communication overhead (updates) 와 idling (stalling in invalidates) 에서 절충해야 한다. 현재 추세는 무효화 프로토콜을 쓰므로 나머지 멀티프로세서 캐쉬 시스템은 무효화 프토콜로 가정한다.
Invalidate Protocols 를 이용한 Cache Coherence 유지
메모리에 있을때는 공유상태, 한 프로세서 p0가 변수를 로드 하면, 이 변수는 더티 혹은 수정 상태로 표시됨 (flag) 이 상황에서 p1이 변수를 받고 싶다하면, p0이 값을 보내주고 메모리에 새로운 값을 업데이트 함. 이후에 변수는 맨 처음과 같이 공유 상태로 됨.
무효 상태의 값을 프로세서가 읽으면, 이 무효 블록은 값을 내려받고 공유상태로 돌아감. 비슷하게 프로세서가 공유 블록에 값을 적으면 무효 블록에 값을 줌. 이러면 다른 공유 블록들 모두 무효 블록이 되어버림.